基本操作
示例数据为 economics 数据集:
| |
date |
pce |
pop |
psavert |
uempmed |
unemploy |
| 0 |
1967-07-01 |
507.4 |
198712 |
12.5 |
4.5 |
2944 |
| 1 |
1967-08-01 |
510.5 |
198911 |
12.5 |
4.7 |
2945 |
| 2 |
1967-09-01 |
516.3 |
199113 |
11.7 |
4.6 |
2958 |
| 3 |
1967-10-01 |
512.9 |
199311 |
12.5 |
4.9 |
3143 |
| 4 |
1967-11-01 |
518.1 |
199498 |
12.5 |
4.7 |
3066 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # 读取数据
df = pd.read_csv("economics.csv", encoding='utf-8', nrows=500, skiprows=[1,2,3])
# 写出数据(to_csv|to_excel|to_json|to_pickle)
df.to_csv('output.csv', index=None)
md_text = df.to_markdown()
with open('output.md', 'w') as f:
f.write(md_text)
# 数据索引
df.loc[8]
df.loc[8, 'date']
df.loc[range(4, 6)]
# 逻辑筛选
df[df.date == '1967-10-01']
df[df.date == '1967-10-01' & ~(df.date == '1967-10-02')] # 与非
df[df.date.isin(['1967-10-01', '1967-10-02'])]
# 绘图
df.pce.plot(); plt.show()
|
进阶操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 读取大型数据集
df_chunk = pd.read_csv('color_all_vggfc6.csv', chunksize=int(1e5)) # 此处只是定义了一个可迭代的 chunk 对象,还没有读入内存
chunk_list = []
for chunk in df_chunk:
chunk_list.append(chunk)
# 可手动控制读取多少
# 频数统计
df.uempmed.value_counts()
# map、apply、applymap等常用函数参考另一篇文章
# 相关性和相关矩阵
df.corr()
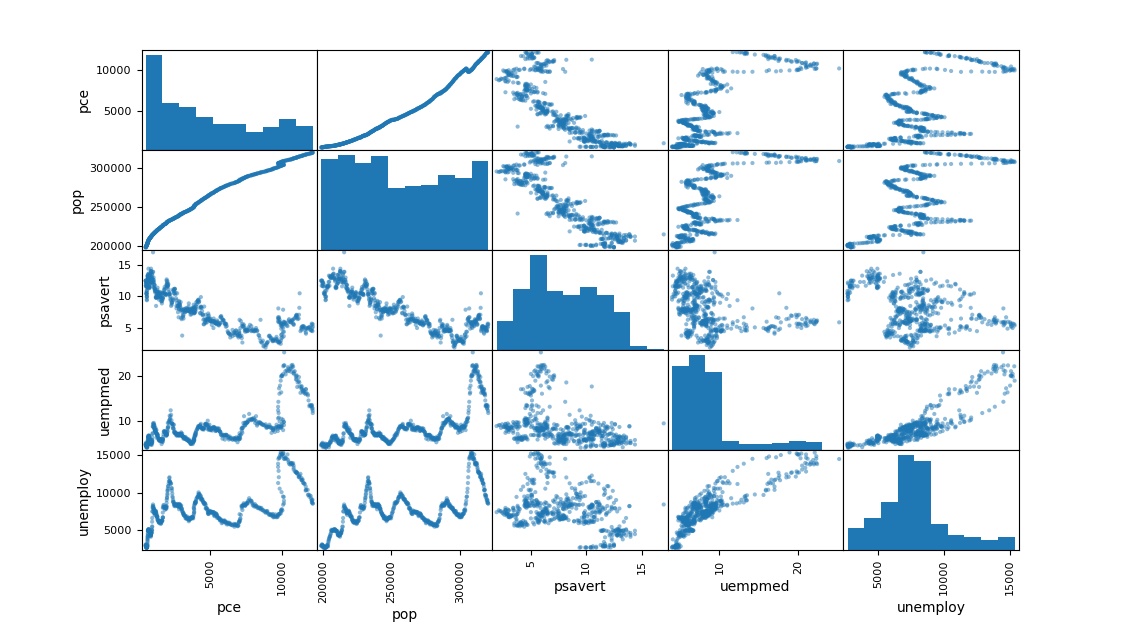
pd.plotting.scatter_matrix(df, figsize=(12, 8))
|
相关系数
| |
pce |
pop |
psavert |
uempmed |
unemploy |
| pce |
1 |
0.987278 |
-0.837069 |
0.727349 |
0.614 |
| pop |
0.987278 |
1 |
-0.875464 |
0.695944 |
0.63403 |
| psavert |
-0.837069 |
-0.875464 |
1 |
-0.387416 |
-0.354007 |
| uempmed |
0.727349 |
0.695944 |
-0.387416 |
1 |
0.869406 |
| unemploy |
0.614 |
0.63403 |
-0.354007 |
0.869406 |
1 |
相关矩阵图
代码加速
原始代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| '''使用seaborn内置的iris数据集,根据petal_length对全部观测进行分类'''
# 分类函数
def classification(petal_length):
if petal_length <= 2: return 1
elif 2 < petal_length < 5: return 2
else: return 3
# 直接使用for循环遍历
class_list = []
start = time.time()
for i in range(len(iris)):
n = classification(iris.loc[i, 'petal_length'])
class_list.append(n)
print(f'>>> for循环耗时:{time.time()-start} 秒')
|
使用迭代器,生成器减少内存占用实现加速
1
2
3
4
5
6
7
8
9
| # 使用 iterrows() 函数进行加速
class_list = []
start = time.time()
for index, row in iris.iterrows():
n = classification(row['petal_length'])
class_list.append(n)
print(f'>>> iterrows()耗时:{time.time()-start} 秒')
|
利用矢量化运算实现加速
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # 使用 apply() 函数进行矢量化运算
start = time.time()
row_to_class_func = lambda row: classification(row['petal_length'])
class_list = iris.apply(row_to_class_func, axis=1) # axis=1时对每行进行apply
print(f'>>> apply()耗时:{time.time()-start} 秒')
# 使用 cut() 函数进行分类减少耗时
start = time.time()
class_list = pd.cut(x=iris.petal_length,
bins = [0, 2, 5, 1e4],
include_lowest = True,
labels=[1, 2, 3]
).astype(int)
print(f'>>> cut()耗时:{time.time()-start} 秒')
|
结果: 使用 apply 函数比 for 循环快,使用 cut 函数最快,应该多使用 pandas 内置的高效函数。iterrows 的加速效果不明显,因为数据集太小,内存占用对程序的影响微乎其微。