简介
Seaborn是一个使用Python制作统计图形的库。它基于matplotlib构建,并与pandas数据结构紧密集成。Seaborn旨在使可视化成为探索和理解数据的中心部分。其面向数据集的绘图功能在包含整个数据集的数据框和数组上运行,并在内部执行必要的语义映射和统计汇总,以生成有用的图。
Seaborn 官方文档
关联
1
2
3
4
5
6
7
# 二维数据
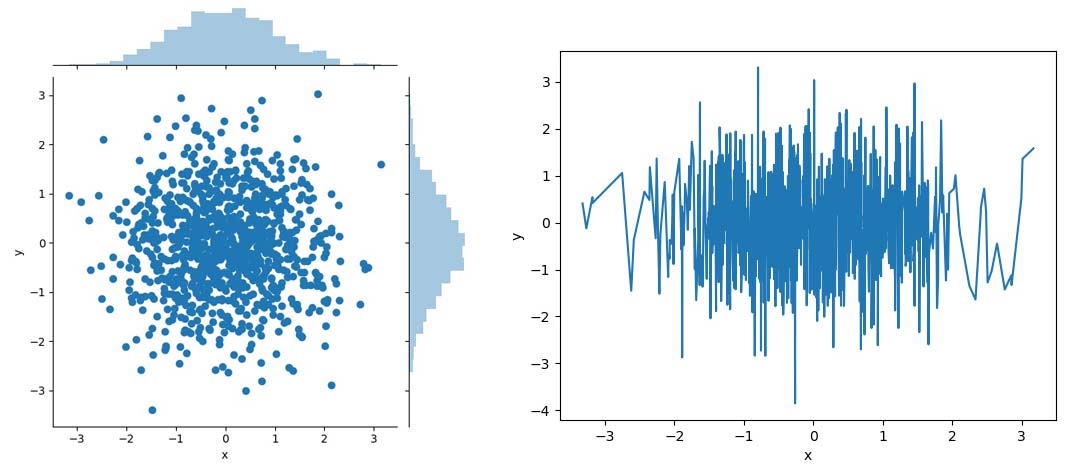
df = pd.DataFrame(np.random.randn(1000,2), columns=['x', 'y'])
# 带单变量分布的关联散点图
sns.jointplot(x='x', y='y', data=df, kind='scatter')
# 折线图
sns.lineplot(x='x', y='y', data=df)
分布
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 一维数据
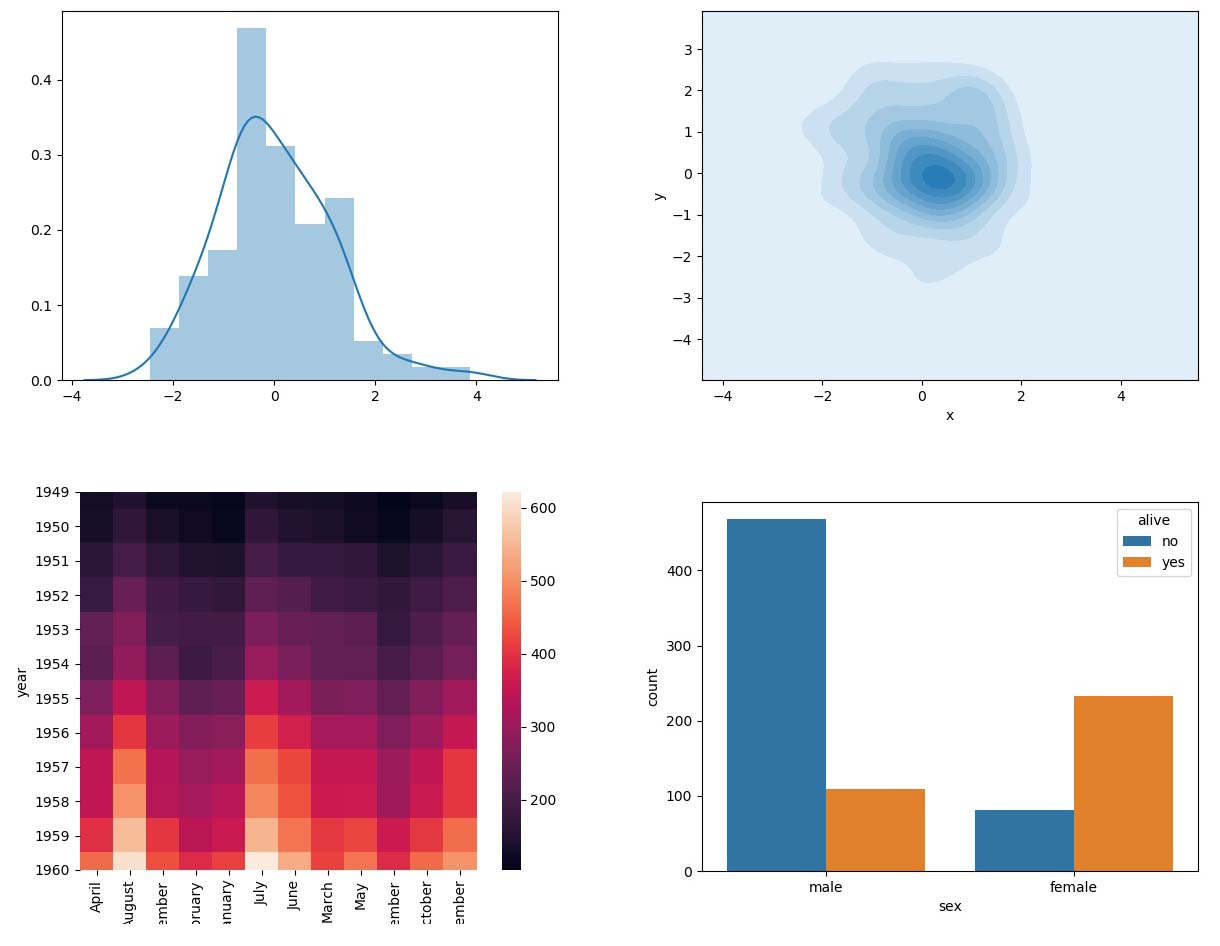
s = pd.Series(np.random.randn(100))
# 带核密度估计的直方图
sns.distplot(s, kde=True)
# 二维数据
df = pd.DataFrame(np.random.randn(100,2), columns=['x', 'y'])
# 二维核密度估计
sns.kdeplot(x='x', y='y', data=df, shade-True)
# 三维数据(数据来源:https://github.com/mwaskom/seaborn-data)
flights = pd.read_csv('seaborn-data-master/flights.csv')
# pandas的透视表功能
data = flights.pivot('year', 'month', 'passengers')
# 热力图
sns.heatmap(data)
# 离散变量数据
titanic = pd.read_csv('seaborn-data-master/titanic.csv')[['sex', 'alive']]
# 分类直方图
sns.countplot(x='sex', hue='alive', data=titanic)
多变量相关关系
1
2
3
4
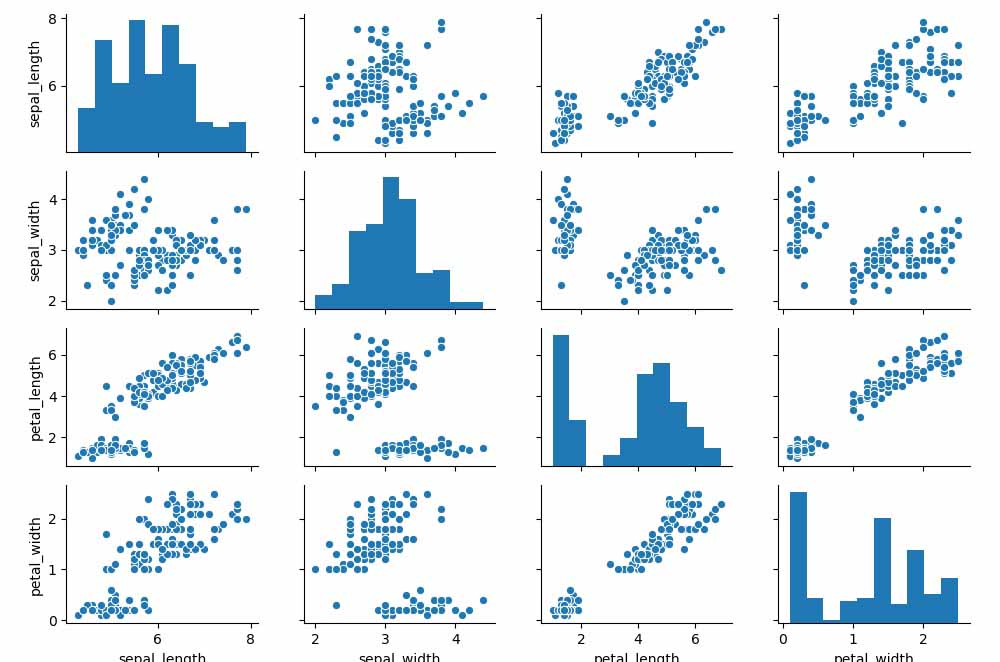
# N 维数据
iris = pd.read_csv('seaborn-data-master/iris.csv'
# 散点图矩阵
sns.pairplot(iris)
总结
通过以上例子可以看到,seaborn 可以很便捷地几乎“一键”生成漂亮的、表述清晰的图像,省去了使用 matplotlib 一个个底层元素进行拼凑的麻烦。并且函数本身有大量参数可以调整。这里不具体进行演示,使用根据需要查看相应文档。