一、简介
首先需要明确数据需求,以及需要用爬虫来做什么。一切需要做大量重复性操作的任务,都可以交给爬虫。换句话说,爬虫跟普通的程序没有本质区别,都是将任务打包成脚本自动执行。唯一的区别就是多了向网站请求数据这一步。关于爬虫可以做什么,参考以下GitHub项目:
爬虫的方法也有很多,Python、R 等编程语言乃至 Excel 都可以爬取网络数据。就python来说,也有很多常用的爬虫框架,例如 PySpider、Scrapy。这里暂时不考虑爬虫框架,因为除了需要大规模的爬虫,使用 requests 和 selenium 可以轻松完成大部分数据获取任务。
这里有一个很棒的博客:
二、网页分析
2.1 URL
明确了所需的数据,就可以上网找数据。这里以豆瓣电影为例子,假设需要研究某部影片的评分情况。进入以下网页:
就可以看到相应电影的短评。尝试翻页,可以看到对应的 URL 随之改变:
https://movie.douban.com/subject/2334904/comments?start=20&limit=20&sort=new_score&status=P
上面“?”后面增加内容就是访问对应页面需要在 URL 中传递的参数,例如 “start=20”表示从第 20 条短评开始,“limit=20”表示每页显示 20 条短评,这个就是在接下来构造 URL 进行翻页时需要改变的参数。有些网站还需带上其他参数。
2.2 F12
在浏览器进入开发者模式就可以看到网页的具体构造,下面是几个需要注意的地方。
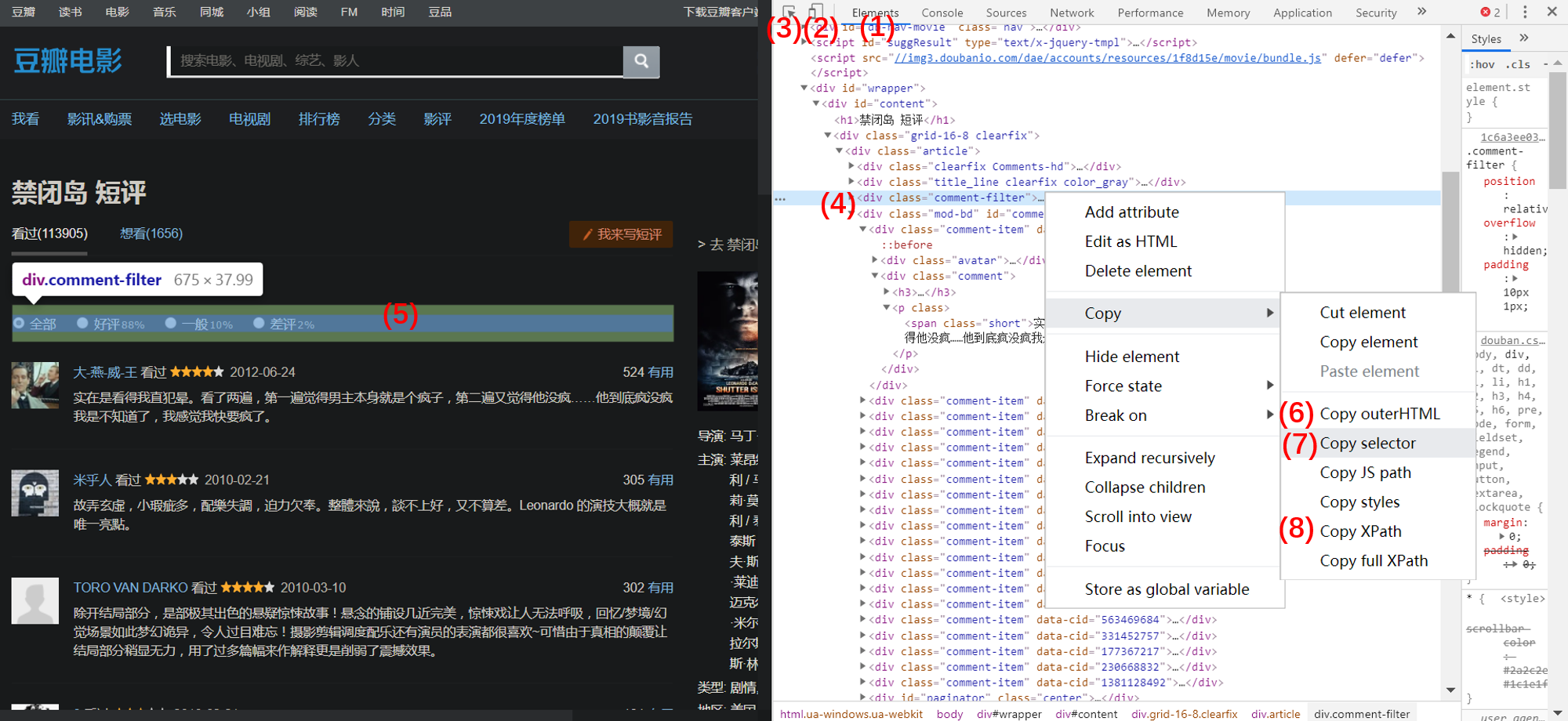
首先进入上图(1)Elements 这一栏,可以看到网页的源码。点击按键(2),大部分网页会切换成移动端,但是这里豆瓣短评页好像无效,只是更改了显示的分辨率。切换成移动端 URL 会随之改变,并且请求数据的方式也会改变。一般这时候会变成 Ajax 动态加载,可以找到 json 数据的接口(作为前端小白摸索出来的,不确定对,原理也不懂~)。点击(3)后,可以随便点击页面的内容,右边会自动展开到对应的源码。也可以鼠标悬停到某个标签(4),这时候页面的内容会高亮(5)。右键对应的标签,可以复制对应的 HTML 代码、XPath 以及 CSS 选择器。
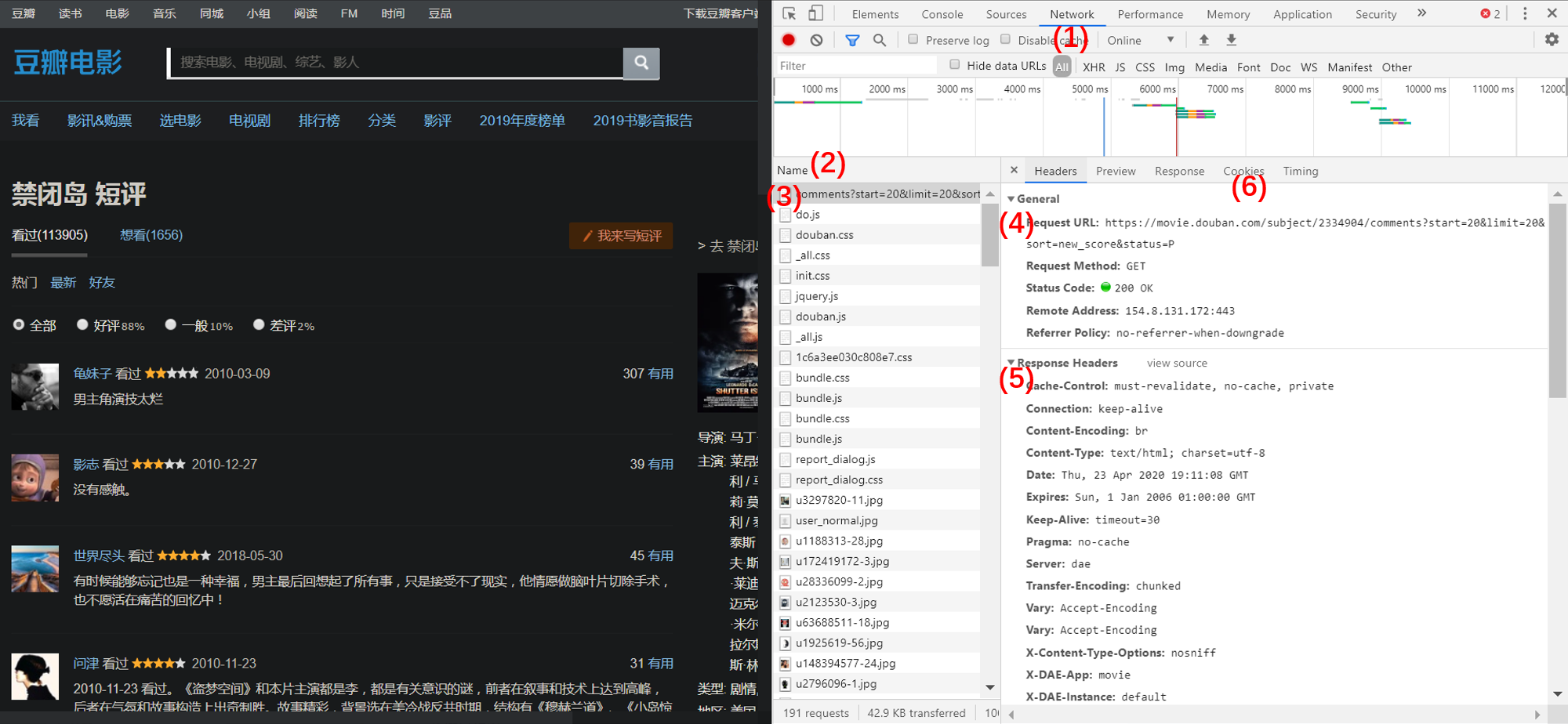
然后进入上图的(1)Network 一栏,可以看到请求的数据流(2),可以理解为搭建起这个页面的一些文件脚本。从文件名可以容易找到我们需要的数据(3),如果这里是动态加载,可以在(4)中得到对应 json 数据的接口链接。在 Headers 中可以看到(4)请求的 Headers 和(5)响应的内容,一般如果直接在爬虫中请求返回状态会不正常,需要将这些 Headers 加上去。而 Cookies(6)中包含了登录状态等会话信息,如果网站需要登录验证再进行后续操作,则需要传入 Cookies 参数。
三、反爬破解
常见的反爬手段上面已经提到两个,主要是需要传递正确的 Headers 和 Cookies 参数。除此之外还有文字反爬、js/css反爬、ip地址反爬、验证码反爬等。一般来说这些反爬措施都可以破解,主要是增加获取数据的门槛和成本。对于较复杂的反爬可以尝试使用 selenium,如果无效再考虑其他办法。例如对于验证码,可以利用 OCR 文字识别,对于ip反爬,可以构建代理池。但是需要尽量遵守 robot 协议,遵守法律和江湖道义,否则牢底坐穿警告[FBI Warning]。
3.1 传入随机 Headers 以及更完整的 Headers 参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)"
]
headers = {
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Host': 'www.yanglee.com',
'Referer': 'http://www.yanglee.com/Product/Index.aspx',
'User-Agent': random.choice(USER_AGENTS), # 随机 user agent
'X-Requested-With': 'XMLHttpRequest'
}
3.2 使用代理 IP
1
2
3
4
5
6
7
8
9
10
11
12
13
# 构建代理池
proxy_list = [
{'http':'125.40.29.100:8118'},
{'http':'14.118.135.10:808'},
...
]
proxy = random.choice(proxy_list)
# 借助 urllib 库,创建 handler 和 opener
handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(handler)
# 发起请求,获取响应内容并解码
response = opener.open(request).read().decode()
3.3 传入 Cookies 参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# -*- coding: utf-8 -*-
# 代码测试实例参考 spider16
import re
import requests as rq
from numpy import random
class MySpider:
'''
__init__:传入有效cookie,接下来每次请求从 RequestsCookieJar 中跟新上次请求返回的cookie
cookie_to_dict: 将初次传入的复制过来的 cookie 转化为字典,再传给 rq.get 函数
get_page: 获取一页,返回包含数据的html文本和相应中跟新的cookie
'''
def __init__(self, cookie, url):
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36'
}
self.cookie_init = cookie # 在浏览器请求第一页,在 cookie 失效前传入并运行爬虫
self.cookie = self.cookie_to_dict()
def cookie_to_dict(self):
names, values = [], []
# 分割字段
ck = self.cookie_init.split('; ')
# 分割键值对
for c in ck:
names.append(re.compile(r'(.*?)=.*?').findall(c)[0])
for i in range(len(names)):
values.append(ck[i].replace(names[i]+'=', ''))
# zip成元组再转换成字典
return dict(zip(names, values))
def update_cookie(self):
'''随便写的测试功能,好像每个网站的 Cookies 的更新和 expire 方式都不一样;
移植时需要 override 这个函数。
'''
num_list = self.cookie['__a'].split('.')
num = int(num_list[-1])
for i in [-1, -2, -4]:
num_list[i] = str(num + 1)
self.cookie['__a'] = '.'.join(num_list)
k = list(self.cookie.keys())[-2]
v = self.cookie[k]
self.cookie[k] = str(int(v) + 100 + random.randint(30))
def get_page(self, page):
resp = rq.get(self.url.format(page), headers=self.headers, cookies=self.cookie)
# 将响应cookies并入初始cookies(这个方法也可能无效)
self.cookie.update(rq.utils.dict_from_cookiejar(resp.cookies))
# self.update_cookie() # 自定义规律更新cookies
return resp
3.4 使用 OCR 识别验证码
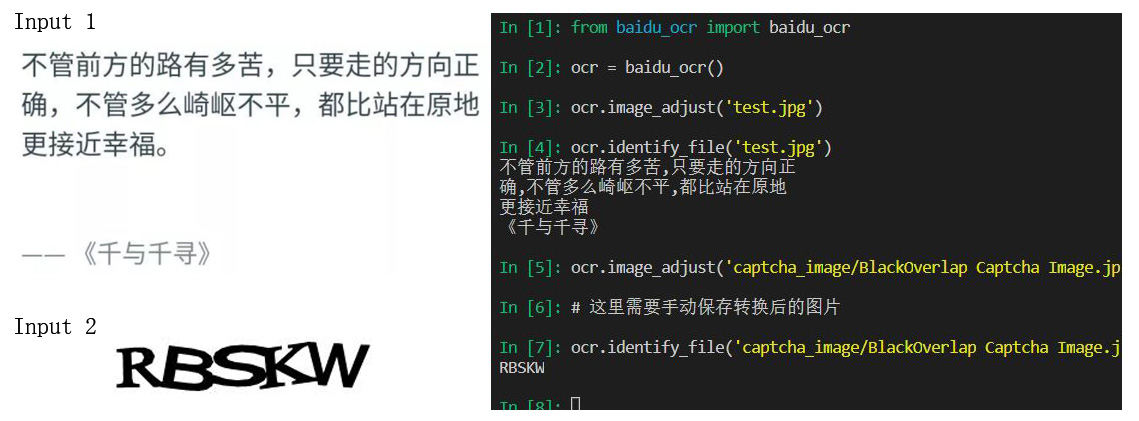
对于验证码反爬,下面是一个使用 百度AI 的 OCR 接口进行验证码识别的例子。首先到上面网站申请 OCR 接口,获取 APP_ID、API_KEY 和 SERET_KEY。首次使用需要 pip install baidu-aip。如果不喜欢百度的也可以使用 tesseract,更加简单方便。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# -*- coding: utf-8 -*-
from aip import AipOcr
from PIL import Image, ImageFilter
class baidu_ocr():
"""识别图片中的文字"""
def __init__(self, AI='__', AK='__', SK='__'):
'''initialize API'''
self.client = AipOcr(AI,AK,SK)
def get_file_content(self, filename):
'''读取图片二进制编码'''
with open(filename,'rb') as f:
return f.read()
def image_adjust(self, filename):
'''优化图片提高识别准确率'''
image = Image.open(filename)
image = image.convert('L') # 灰度化
image = image.convert('1') # 二值化
image = image.filter(ImageFilter.FIND_EDGES) # 寻找边缘
image = image.filter(ImageFilter.EDGE_ENHANCE) # 边缘增强
image.show()
def identify_image(self, image, lan='CHN_ENG', out='outfile'):
'''识别图像文字'''
# 设置参数
options={
# 自动识别图像方向
'detect_direction':'True',
# 识别语言类型一般设置为'CHN_ENG'中英文混合
'language_type': lan,
}
# 调用通用文字识别接口
result = self.client.basicGeneral(image, options)
# 写出结果
for word in result['words_result']:
print(word['words'])
with open(f'{out}.txt', 'a+', encoding='utf8') as f:
f.writelines(word['words'] + '\n')
def identify_file(self, filename='test.jpg'):
image = self.get_file_content(filename)
self.identify_image(image)
四、请求数据
4.1 使用 requests 请求数据
1
2
3
4
5
url = 'http://book.douban.com/latest'
UA = "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36"
headers = {'User-Agent': UA}
# 加入 headers,注意要使用 kwarg
response = requests.get(url, headers=headers)
异常处理: 爬虫程序运行时容易出现某次请求不成功的情况,为了避免由于意外错误导致程序终止而丢失之前获取的数据,可以使用异常处理方法。
1
2
3
4
5
6
7
for url in urls:
try:
res = rq.get(url)
except Exception as e:
print(e)
continue # 一般情况可以直接跳过本次请求
time.sleep(3) # 增加 pause 避免被封 IP 或造成服务器压力
网页响应转码: 有时候响应正常但是显示乱码,是因为编码没有对应上,需要手动进行转码。
1
2
3
4
5
6
7
8
9
10
test_url = "http://search.51job.com"
response = rq.get(test_url, headers=headers)
def solve_coding(response, out_coding='gbk'):
'''将响应的默认编码转为合适的编码'''
html = response.text.encode(response.encoding).decode(out_coding)
print(f'已经由 {response.encoding} 编码转换成 {out_coding} 编码')
return html
html = solve_coding(response)
4.2 使用 selenium 请求数据
selenium 支持 PhantomJS 或浏览器驱动,这里使用 chromedriver。下载正确对应版本的驱动器,放到 python.exe 所在目录便可以使用。一般对性能要求不高,而反爬措施复杂的爬虫,较适合使用 selenium 获取数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from selenium import webdriver
# 设置无图浏览模式,提高效率(一般爬虫只需要文本数据)
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
# driver = webdriver.Chrome(chrome_options=options)
# 创建浏览器自动化测试实例,并打开网址
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
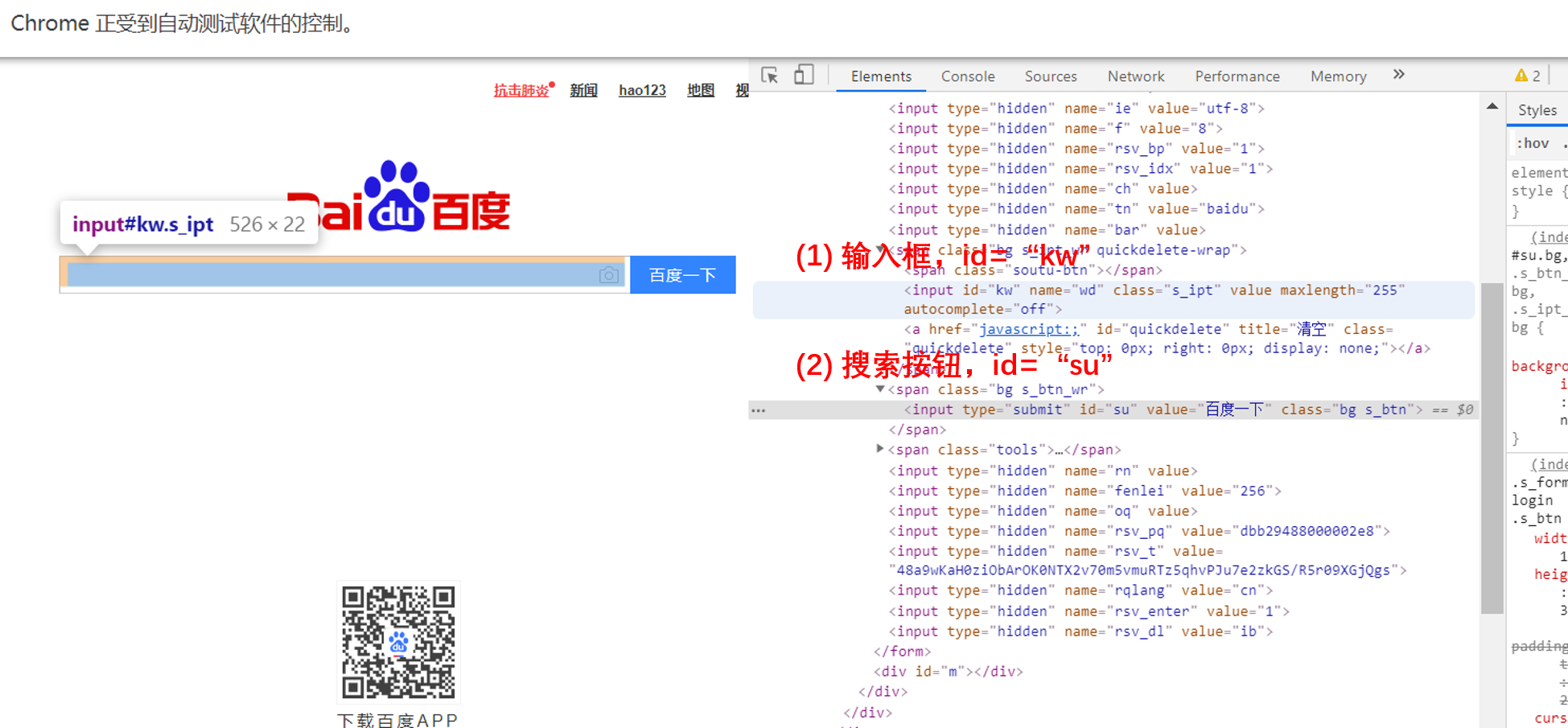
# 定位输入框,输入字符
driver.find_element_by_id('kw').send_keys('天气') # 根据元素的 id 定位元素
# 定位提交按钮,点击
driver.find_element_by_id('su').submit() # 也可以使用 click 函数
# 在浏览器开发模式中复制相应元素的 selector
selector = 'div.op_weather4_twoicon_container_div > div.op_weather4_twoicon > a.op_weather4_twoicon_today.OP_LOG_LINK'
# 改为 elements,由惰性匹配改为全文匹配(用于爬取列表很方便)
print(driver.find_elements_by_css_selector(selector)[0].text)
# text 获取除去 html 格式的文本:
'04月25日 周六 农历四月初三 \n17\n℃\n阴(实时)\n17 ~ 22℃\n阴\n无持续风向微风\n41 优'
# 使用 get_attribute 方法获取 HTML 文本
driver.find_elements_by_id('weather').get_attribute('outerHTML')
# 完成后关闭浏览器实例,或可以新建标签和窗口
driver.close()
# 更多的元素定位和元素操作函数可查看 WebDriver 类的文档
help(selenium.webdriver.chrome.webdriver.WebDriver)
# 使用 PhantomJS(可在浏览器调试好程序在切换到 PhantomJS 执行)
driver = webdriver.PhantomJS(executable_path = r'C:/Program Files/PhantomJS-2.1.1-Windows/bin/phantomjs.exe')
driver.get('http://www.baidu.com/')
print(driver.find_element_by_class_name('title').text)
4.3 使用 pandas 请求数据
使用 pandas 的 read_html 函数可以直接解析网页中包含的表格数据。这个方法非常简单快捷,但是不够稳健,因为网页的内容会改变,每次使用都需要稍微修改代码。对于需要计划运行的爬虫,需要用更精准更稳健的方法(比如可以先请求一遍确定表格的位置内容无误,再用 pandas 快速获取)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
for i in range(1,10):
url = f'http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum={i}')
tb = pd.read_html(url)[3] # 所需表格是网页中的第四个表格
tb.to_csv(r'stock_info.csv', mode='a', encoding='utf-8', header=1, index=0)
print('第' + str(i) + '页抓取完成')
# read_html 函数详解:
'''
pandas.read_html(io, match=".+", flavor=None, header=None, index_col=None,
skiprows=None, attrs=None, parse_dates=False, tupleize_cols=None,
thousands=',', encoding=None, decimal=',', converters=None,
na_values=None, keep_default_na=True, displayed_only=True)
'''
# 注意:返回的结果是 DataFrame 组成的 list
# 常用的参数:
'''
# io:可以是url、html文本,本地文件等;
# flavor:解释器
# header:标题行
# skiprows:跳过的行
# attrs:属性,例如:attrs={'id':'table'}
# parse_dates:是否解析日期
'''