直接跳转到分析结果
一、问题背景
电商平台每日产生海量的订单,尤其是诸如 “618” 和 “双十一” 等活动期间,巨额的成交量之下,必然产生巨量的数据。面对这些数据,如何提取有用的信息?如何根据业务需求确定 KPQ 和 KAQ ?如何设计相应的指标体系以量化业务流程?如何发掘数据的最大价值?如何通过量化的指标做出决策指导?面对这些“灵魂拷问”,我们还是要从业务入手。
二、分析思路
在电商数据分析中有很多既成的模型、指标体系以及分析方法。虽然的确可以直接套用某个模型进行分析,但是这里为了逻辑更清晰,将从战略到业务、从业务到指标,一步步得出分析模型。
2.1 战略分析
首先把数据分析的服务对象定义为决策者,我们的目标是优化运营策略和用户策略。对于淘宝这样一个成熟的平台,关注的主要问题有客户价值、获客成本、渠道质量,等。但是由于整个平台业务流程深、业务模块复杂,需要先具体化分析问题。这里把关键分析问题定义为:如何提高总成交额? 例如,通过什么样的运营策略可以提高双十一活动期间的 GMV ?
2.2 理解相关业务
确定了服务的对象和分析的问题,接下来需要分析业务流程。在流程中拆解业务模块,细化出直接或间接影响了 KAQ 的环节,最后用指标对其进行量化。例如我们现在关注的是销量和成交额的问题,则应该从商品销售的过程中进行分析。下图大致总结了淘宝上销售商品的业务流程:
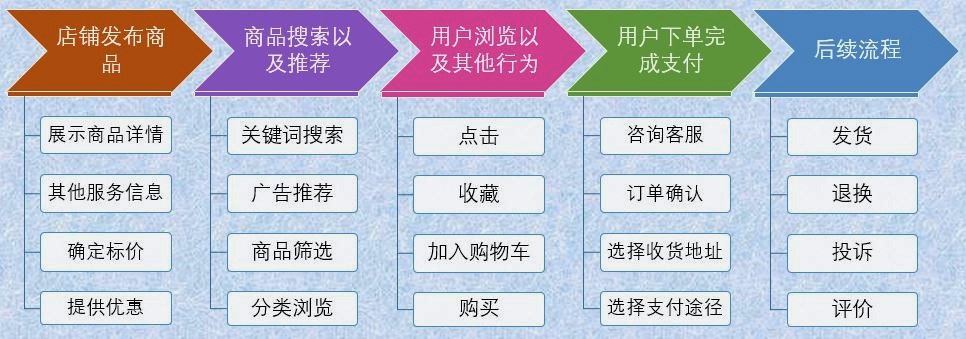
根据业务流程,通过公式化进行拆解,便可以得到详细的指标。在这一例中,成交额可以用公式表示为:

通过不断的拆解,就可以把关键分析问题转化为业务流程中的指标。根据不同的服务对象和业务需求,穷举所有的关键分析问题。例如上文提到的客户价值,渠道比例等问题。再对这些问题进行一一拆解,便可以形成一个完整的数据分析指标体系,部署在业务流程中。
2.3 构建指标体系
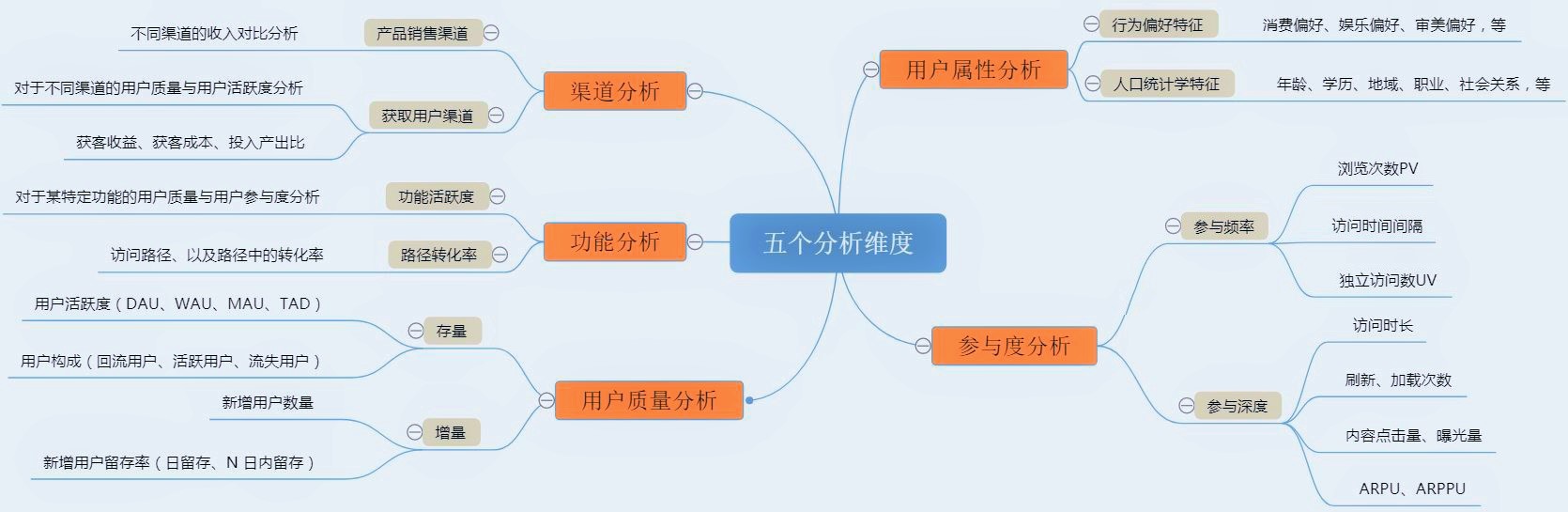
为了避免漫无边际地罗列数据,以业务为逻辑来构建分析指标体系尤其重要。按照业务流程中需要量化的内容,可以将数据指标大致分为三个过程五个维度。
以业务流程作为拆解逻辑,可以分为:用户获取 –> 用户行为 –> 业务结果。按指标的不同维度进行拆解,可以分为:用户属性分析、用户质量分析、参与度分析、渠道分析、功能分析。根据这五个维度,分别对应三个过程进行拆解,便可以得到具体的指标。下图为类似于淘宝的电商平台的指标体系示例:
2.4 数据获取
确定了数据指标体系,需要明确定义指标,才能交付部署,收集相关数据。通常的数据收集包括埋点、爬虫,以及寻求第三方提供的数据库。
简单来说,埋点就是在网页、移动端或者服务器中预置的收集数据并存储数据的程序。确定埋点方案主要分为几个步骤:
- 明确埋点需求:通过分析业务,建立指标体系,根据具体指标确定埋点需求;
- 明确属性定义:对事件、用户行为以及业务成果进行明确定义;确定在前端收集还是后端收集;
- 有效性检验:确定数据可得性和来源,初步获取数据,对比预期结果;
- 生成数据需求文档:将与埋点相关的业务逻辑、属性定义、数据来源等信息,总结为数据需求文档(DRD),在开发过程中部署埋点;
- 后期的维护与迭代。
2.5 数据分析
数据分析的方法模型有很多,需要根据应用场景确定分析方法和评估模型。进行数据分析时需要基于业务,除了计算相关的指标,还需要输出其他的发现。最大程度挖掘数据的价值,服务于业务的优化。
常用的数据分析方法有两个方面:
- 统计分析:统计学意义上对数据的洞察,包括计算关键指标、不同维度的分布、相关性、联合分布、趋势,等。
- 数据挖掘:通过机器学习方法生成模型,预测数据的趋势,或者发现数据的模式;包括回归分析、分类、聚类,等。
好的数据分析方法,需要在业务层面上产生指导价值。除了计算相关的指标、学习相关的模型,还需要确定分析结果在业务上的意义。常用的方法有:归因查找、漏斗分析、对比分析、行为序列分析、多维度拆解,等。
三、实战分析
3.1 理解数据
按照分析的需求,我们这里需要获取的是淘宝平台上的订单数据、商品数据、用户行为数据,等。下一步,上爬虫! 由于这些信息没有公开,无法在网上抓取。但是有部分官方数据经过脱敏后公开,作为科研竞赛等用途,可以有限制地获得。以下是阿里天池公开的淘宝用户行为数据:User Behavior Data From Taobao for Recommendation
| 字段 | 说明 |
|---|---|
| 用户ID | 整数,共987,994个用户 |
| 商品ID | 整数,共4,162,024个商品 |
| 商品类目ID | 整数,共9,439个商品类别 |
| 行为类型 | 字符串,枚举类型(pv–点击、buy–购买、cart–加入购物车、fav–收藏),共100,150,807个行为 |
| 时间戳 | 行为发生的时间,使用 UNIX 时间戳表示(2017-11-25 ~ 2017-12-03) |
从上表可以看到,数据包含五个字段和一亿条观测。从数据的内容,我们根据前面的五个分析维度,简单罗列一下从数据源中可能获得的信息:
- 用户属性:用户的行为特征
- 参与度:PV、UV、时间间隔、ARPU,等
- 用户质量:DAU、WAU、TAD、单日留存、周留存,等
- 功能:路径转化率
- 渠道:无信息
3.2 构建数据集
上面的源数据解压后达到 3.5GB,无法直接写进内存进行分析。这里使用 pandas 进行分块,并使用 sqlalchemy 引擎写进数据库,提高后续的处理效率。
首先在数据库中创建一个新的 Table,定义各个字段。这里由于每个用户ID对应多个行为序列,不能作为主键,选取三个字段作为联合主键。
1
2
3
4
5
6
7
8
CREATE TABLE IF NOT EXISTS User_Behaviors(
user_id INT(20) NOT NULL,
item_id INT(20) NOT NULL,
cat_id INT(20) NOT NULL,
behav_type VARCHAR(20) NOT NULL,
time_stamp INT(20) NOT NULL,
PRIMARY KEY (user_id, item_id, time_stamp)
)
然后将数据分块读取存进数据库。由于源数据中没有字段名,这里需要给 DataFrame 手动加上字段名。
1
2
3
4
5
6
7
8
9
10
11
12
13
chunks = pd.read_csv('UserBehavior.csv', chunksize=10000, header=None)
cols = ['user_id', 'item_id', 'cat_id', 'behav_type', 'time_stamp']
engine = sqlalchemy.create_engine(
f'mysql+pymysql://root:{pw}@localhost:3306/{db}?charset=utf8'
)
for df in chunks:
df.columns = cols
df.to_sql(
'User_Behaviors',
con=engine,
if_exists='append',
index=False
)
存进数据库后需要进行数据的清洗,主要包括将 UNIX 时间戳转化成 Ymd-HMS 格式的时间、删除一些异常数据。
1
2
3
4
5
6
7
8
9
10
ALTER TABLE user_behaviors ADD COLUMN `datetime` TIMESTAMP(0) NULL;
ALTER TABLE user_behaviors ADD COLUMN `date` CHAR(10) NULL;
ALTER TABLE user_behaviors ADD COLUMN `hour` CHAR(10) NULL;
UPDATE user_behaviors SET `datetime` = FROM_UNIXTIME(time_stamp);
UPDATE user_behaviors SET `date` = SUBSTRING(datetime FROM 1 FOR 10);
UPDATE user_behaviors SET `hour` = SUBSTRING(datetime FROM 12 FOR 2);
DELETE FROM user_behaviors WHERE
datetime < '2017-11-25 00:00:00' OR datetime > '2017-12-04 00:00:00';
作为分析示例,这里抽取了数据集中前 100 万行观测进行分析。虽然 SQL 的查询高度优化,每条语句的执行还是需要几秒钟。如果处理整个数据集(一亿行),将会达到几分钟,需要再进一步优化,或者使用 mapreduce 程序。
3.3 计算相应指标
(1)用户活跃度
下面计算了每天的活跃用户数量,并以11-26(周日)~12-02(周六)为一周,计算周活跃用户数量。留意到数据源里有记录的用户,均为产生过行为的用户,因此不能以活跃数量来分析用户质量。为了分析用户质量,这里可以计算每个用户的总活跃天数以及活跃时段分布。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
-- 计算每一天的 DAU
SELECT date AS '日期', COUNT( DISTINCT user_id ) AS 'DAU'
FROM user_behaviors
GROUP BY date;
-- 类似地计算 WAU
-- SELECT ... FROM ... WHERE date >= '2017-11-26' OR date <= '2017-12-02';
-- 计算每个用户的 TAD,保存为视图
CREATE VIEW TAD AS
SELECT user_id AS '用户ID', COUNT(DISTINCT date) AS 'TAD'
FROM user_behaviors
GROUP BY user_id
ORDER BY TAD DESC;
-- 通过 TAD 视图计算活跃天数的分布
SELECT `TAD`, COUNT(DISTINCT '用户ID') AS '人数'
FROM TAD
GROUP BY `TAD`
ORDER BY `TAD` DESC;
-- 计算不同时段的活跃用户数量
SELECT hour, COUNT(DISTINCT user_id) AS '活跃数量'
FROM user_behaviors
GROUP BY hour
ORDER BY hour;
| 日期 | 11-25 | 11-26 | 11-27 | 11-28 | 11-29 | 11-30 | 12-01 | 12-02 | 12-03 | | | WAU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DAU | 6,976 | 7,128 | 7,026 | 7,032 | 7,141 | 7,243 | 7,270 | 9,567 | 9,561 | | | 9739 |
| Hour | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ActiveNum | 3,091 | 1,613 | 980 | 700 | 628 | 852 | 1,743 | 3,274 | 4,368 | 5,157 | 5,759 | 5,812 | 5,874 | 6,056 | 5,875 | 5,987 | 5,989 | 5,773 | 5,684 | 6,210 | 6,549 | 6,709 | 6,441 | 5,034 |
| BuyNum | 384 | 155 | 91 | 47 | 54 | 59 | 122 | 300 | 479 | 713 | 952 | 916 | 917 | 948 | 874 | 890 | 896 | 789 | 690 | 834 | 991 | 1,042 | 955 | 647 |
| CVR (%) | 12.4 | 9.6 | 9.3 | 6.7 | 8.6 | 6.9 | 7.0 | 9.2 | 11.0 | 13.8 | 16.5 | 15.8 | 15.6 | 15.7 | 14.9 | 14.9 | 14.9 | 13.7 | 12.1 | 13.4 | 15.1 | 15.5 | 14.8 | 12.9 |
| TAD | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|
| 人数 | 2,592 | 1,997 | 1,730 | 1,399 | 1,146 | 793 | 72 | 8 | 2 |
(2)留存分析
接下来进行留存分析。首先计算新增的用户,由于这里的数据无法计算准确意义上的“新增用户”,这里把“新增”定义为第一次出现购买行为的用户。由于缺乏历史数据,这里的新增数量在前几天存在一定水分,最后稳定到 500~600 之间。以日作为计算留存率的最小单位,默认当天的留存率为 100%。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
-- 创建一个查询过程获取每天的新增用户以及日留存
CREATE DEFINER = CURRENT_USER PROCEDURE `retentRate`(
base INT(20), day_start VARCHAR(20), day VARCHAR(20)
)
-- base -- 基期新增数量 | day_start --基期日期 | day -- 计算当日日期
BEGIN
SET @retentNum = 0;
SELECT COUNT(DISTINCT user_id) INTO @retentNum
FROM user_behaviors WHERE user_id
IN(
SELECT DISTINCT user_id FROM user_behaviors WHERE user_id
NOT IN(
SELECT DISTINCT user_id FROM user_behaviors
WHERE date<day_start AND behav_type='buy'
)
AND date=day_start AND behav_type='buy'
)
AND date=day AND behav_type='buy';
SELECT @retentNum / base AS '留存率';
END
-- 计算 2017-11-25 新增用户数量
CALL retentRate(1, '2017-11-25', '2017-11-25');
-- 计算 2017-11-25 新增用户在 2017-11-26 的单日留存率
CALL retentRate(1317, '2017-11-25', '2017-11-26');
-- 计算总留存率
SELECT COUNT(DISTINCT user_id)
FROM user_behaviors
WHERE date>@day_start
AND behav_type='buy'
AND user_id IN(
SELECT DISTINCT user_id FROM user_behaviors
WHERE date=@day_start AND behav_type='buy'
)
AND user_id NOT IN(
SELECT DISTINCT user_id FROM user_behaviors
WHERE date<@day_start AND behav_type='buy'
);
| 留存分析 | 日期 | 11-25 | 11-26 | 11-27 | 11-28 | 11-29 | 11-30 | 12-01 | 12-02 | 12-03 |
|---|---|---|---|---|---|---|---|---|---|---|
| 新增: | 新增用户数 | 1,317 | 1,036 | 890 | 736 | 654 | 575 | 508 | 543 | 430 |
| 日留存: | 11-25 留存率(%) | 100 | – | – | – | – | – | – | – | – |
| | | 11-26 留存率(%) | 21.9 | 100 | – | – | – | – | – | – | – |
| | | 11-27 留存率(%) | 21.8 | 23.0 | 100 | – | – | – | – | – | – |
| | | 11-28 留存率(%) | 21.5 | 19.6 | 21.1 | 100 | – | – | – | – | – |
| | | 11-29 留存率(%) | 22.3 | 19.9 | 19.8 | 18.6 | 100 | – | – | – | – |
| | | 11-30 留存率(%) | 21.7 | 18.5 | 20.2 | 17.4 | 17.6 | 100 | – | – | – |
| | | 12-01 留存率(%) | 20.7 | 16.3 | 15.8 | 17.8 | 16.5 | 15.3 | 100 | – | – |
| | | 12-02 留存率(%) | 25.9 | 20.4 | 18.3 | 18.6 | 17.6 | 19.0 | 21.1 | 100 | – |
| | | 12-03 留存率(%) | 24.9 | 23.7 | 19.9 | 20.1 | 17.9 | 16.7 | 21.7 | 19.9 | 100 |
| 总留存: | 12-03 总留存(%) | 79.3 | 73.4 | 68.8 | 59.5 | 48.9 | 39.5 | 36.4 | 19.9 | – |
(3)参与度分析
首先计算点击量和独立访客数。然后根据 RFM 模型,计算每位用户的最近一次购买、平均时间间隔、购买次数和复购率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
-- 创建视图,抽样出具有购买行为的用户,计算每个用户的购买次数
CREATE VIEW buy_times AS
SELECT user_id AS '用户ID', COUNT(behav_type) AS '购买次数'
FROM user_behaviors
WHERE behav_type='buy'
GROUP BY user_id ORDER BY '购买次数' DESC;
-- 计算购买次数分布
SELECT '购买次数', COUNT('用户ID') AS '人数'
FROM buy_times
GROUP BY '购买次数' ORDER BY '人数' DESC;
-- 计算最近一次购买
CREATE VIEW recency AS
SELECT user_id, MAX(date) AS '最近一次购买日期', MAX(time_stamp) AS '时间戳'
FROM user_behaviors
WHERE behav_type='buy' GROUP BY user_id;
SELECT COUNT(user_id), '最近一次购买日期' AS `date`
FROM recency GROUP BY date ORDER BY date DESC;
DROP VIEW buy_times, recency;
| 日期 | 11-25 | 11-26 | 11-27 | 11-28 | 11-29 | 11-30 | 12-01 | 12-02 | 12-03 | | | 总和 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PV | 93,932 | 95,657 | 87,243 | 88,637 | 91,334 | 94,735 | 98,138 | 123,514 | 122,446 | | | 895,636 |
| UV | 6,782 | 6,928 | 6,828 | 6,810 | 6,930 | 7,010 | 7,054 | 9,271 | 9,300 | | | 9,706 |
| 购买次数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 用户计数 | 2,260 | 1,574 | 1,041 | 613 | 384 | 259 | 168 | 100 | 73 | 46 |
| 最近购买日期 | 12-03 | 12-02 | 12-01 | 11-30 | 11-29 | 11-28 | 11-27 | 11-26 | 11-25 |
|---|---|---|---|---|---|---|---|---|---|
| 用户计数 | 1,759 | 1,277 | 811 | 744 | 607 | 493 | 398 | 328 | 272 |
计算得 9 日内复购率为 66.2%。由于数据中缺少订单金额,这里将 ARPU 定义为“平均每个用户的购买数量”。可以计算 9 天中的 ARPU 为 每活跃用户 2.1 次购买、ARPPU 为 每付费用户 3 次购买。
接下来计算购买行为时间间隔。先去除单次购买用户,将每个用户的时间戳转化为有序列表,然后计算每个用户购买行为的时间间隔,得出平均时间间隔(亦即购买行为频率;由于数据源时间跨度短,直接用次数除以天数得出的频率不准确)。
(4)其他指标
首先进行功能分析,计算功能访问情况以及路径转化率。根据业务逻辑,将加入购物车与收藏商品归到同一个节点(暂命名为“喜欢”),可计算得结果如下:
| 行为 | 页面浏览 | 加入购物车 | 收藏 | 购买 | | | 浏览-喜欢转化率 | 喜欢-购买转化率 | 浏览-购买转化率 |
|---|---|---|---|---|---|---|---|---|
| 数量 | 895,636 | 55,447 | 28,088 | 20,359 | | | 9.33% | 24.4% | 2.28% |
接下来对不同商品类别进行分析,计算不同类别的商品的点击量和销售量进行排名。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 创建点击量和销售量视图
CREATE VIEW cat_click AS
SELECT cat_id AS 'clickID', COUNT(*) AS '点击量'
FROM user_behaviors
WHERE behav_type='pv' GROUP BY cat_id;
CREATE VIEW cat_sale AS
SELECT cat_id AS 'saleID', COUNT(*) AS '销售量'
FROM user_behaviors
WHERE behav_type='buy' GROUP BY cat_id;
-- 对两个视图进行 内连接,并转化为数据表,添加转化率字段
CREATE VIEW click_sale AS
SELECT * FROM cat_click
INNER JOIN cat_sale ON cat_click.clickID = cat_sale.saleID;
-- 计算各类目转化率
ALTER TABLE click_sale ADD COLUMN rate FLOAT(5,4) NULL;
UPDATE click_sale SET rate = '销售量' / '点击量';
3.4 数据挖掘
这里做数据挖掘的意义是,希望获得对用户的行为模式的洞察。实现精准营销,商品推荐等相关功能。由于源数据只有用户的行为特征,而没有我们需要的响应变量,因此使用无监督学习方法对用户进行分群。
(1)构建训练集
根据掌握的数据,首先需要确定从数据可以获取哪些信息。使用 OpenCV 对用户行为数据进行可视化,如下图:
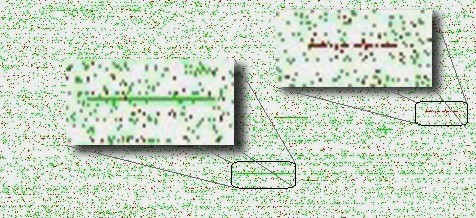
其中每个像素点代表一次用户行为,同一用户行为序列相邻。白色为浏览,绿色为喜欢,红色为购买。将部分放大可以看到,不同用户的行为序列存在特定的模式。接下来需要对数据进行标准化以用于模型训练。为了给离散的分类变量赋予连续的意义,按照业务逻辑,将取值为“cart”与取值为“fav”的观测,合并为“fav”一个节点。最后将行为类型转化为哑变量。
1
2
3
4
5
6
7
8
9
10
""" 构建训练集
"""
# ...
data = pd.DataFrame()
data['user_id'] = df.user_id
data['pv'] = [1 if behav == 'pv' else 0 for behav in df.behav_type]
data['fav'] = [1 if behav in ['cart','fav'] else 0 for behav in df.behav_type]
data['buy'] = [1 if behav == 'buy' else 0 for behav in df.behav_type]
# 求行为序列矢量和
data = data.groupby('user_id').agg(sum)
得到的 DataFrame 包含三个特征变量,每个 user_id 对应三维空间中的多个特征向量。如果用特征向量代表用户的行为序列,将涉及很高的维度,增加模型解析难度。因此只对每个用户的特征向量求矢量和。构建的数据集采样如下:
| user_id | 1 | 100 | 115 | … | 1017997 | 1018000 | 1018011 |
|---|---|---|---|---|---|---|---|
| pv | 55 | 84 | 227 | … | 90 | 181 | 41 |
| fav | 0 | 6 | 14 | … | 3 | 4 | 0 |
| buy | 0 | 8 | 0 | … | 2 | 0 | 1 |
(2)建模评估
K-Means 算法将包含 个样本的变量 分成 个不相交的聚类 ,每个聚类用其样本均值 表示,该均值通常称为“质心”。质心可以不是包含在样本集合 中的点。使用欧氏距离度量,K-Means 算法旨在最小化每个点距离质心的 范数,对应的损失函数如下:

利用 scikit-learn 进行建模训练与模型评估:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
# ...
# 数据归一化
data = df.copy().drop('user_id', axis=1)
data = StandardScaler().fit(data).transform(data)
# 根据轮廓系数进行模型调优
sh_scores = []
km_models = []
for i in range(9):
km = KMeans(n_clusters=i+2)
km.fit(data)
sh = silhouette_score(data, km.labels_)
sh_scores.append(sh)
km_models.append(km)
# ...
# 用户分群标签
df['lables'] = km_models[k-2].labels_
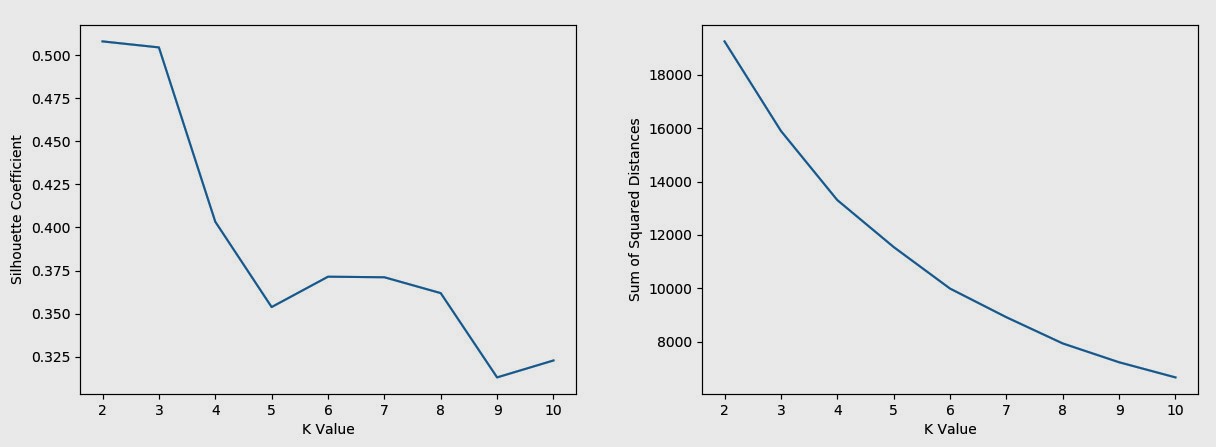
通过下图评估模型质量:左图为轮廓系数,理论上接近 1 越好;右图为质心距离平方和,理论上越小越好。可以看到,由于数据源包含的信息维度较少,聚类趋势并不明显。如果进行进一步的调优,需要增加特征变量,以及在训练集特征变量的权重和尺度缩放等方面进行调整。并且在后期在业务流程中进行跟踪,通过业绩对比以及AB测试等方法确定最优模型。由于可用数据有限,这里仅得出一个较粗糙的结果作为示例。综合两图以及业务上的需求,将 K 值定为 6 ,最后给用户贴上类别标签。
3.5 RFM模型
根据前面计算得到的相关数据指标,建立 RFM 模型对用户价值进行评分。这里 recency 用最近一次购买时间表示;frequency 用购买平均时间间隔表示,只有一次购买的用户的 frequency 取值为所有用户中的最大值;monetary 由于缺少客单价数据,直接用购买次数表示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# ...
# 计算 recency
rfm.recency = list(
df[['user_id', 'time_stamp']].groupby('user_id').agg(max)['time_stamp']
)
# 计算 frequency(日期跨度较短,用平均购买时间间隔表示)
for i in range(len(rfm)):
try:
rfm.frequency[i] = - interval.loc[rfm.user_id[i]].mean_hour
except Exception as KeyError: # interval中仅包含购买次数大于一次的用户信息
rfm.frequency[i] = - max(interval.mean_hour)
# 计算 monetary(缺少客单价,用购买次数表示)
for i in range(len(rfm)):
try:
rfm.monetary[i] = interval.loc[rfm.user_id[i]].buy_times
except Exception as KeyError:
rfm.monetary[i] = 1
# 数据归一化转为评分
def scaler(name, df=rfm):
arr = np.array(df[name])
m = np.median(arr) # 使用中位数对价值高低进行划分
s = np.std(arr)
return list((arr - m) / s)
rfm.recency = scaler('recency')
rfm.frequency = scaler('frequency')
#去除极端值
rfm.monetary = [10 if i >= 10 else i for i in rfm.monetary]
# 添加分群标签:三位编码分别代表r、f、m,A、B分别代表价值高、低。
label = ['A' if i > 0 else 'B' for i in rfm.recency]
label = [lb+'A' if i > 0 else lb+'B' for i, lb in zip(rfm.frequency, label)]
rfm['label'] = [lb+'A' if i>0 else lb+'B' for i,lb in zip(rfm.monetary, label)]
计算出指标后对其进行归一化作为评分。并在三个维度以中位数为分界,将用户分割为 8 群,用从 “AAA” 到 “BBB” 的 8 个标签表示(取值 A 表示该维度评分高于中位值)。得到的数据如下表所示。最后利用 R 中的 3D 绘图库 scatterplot3d 绘制用户的价值分群图像。
| user_id | recency | frequency | monetary | label |
|---|---|---|---|---|
| 102802 | -0.38434464 | 0.229597733 | 1.2305542 | BAA |
| 102795 | 0.49541227 | 0.047177616 | 0.6152771 | AAA |
| 102856 | 0.79183396 | -1.927991923 | -0.3076386 | ABB |
| … | … | … | … | … |
1
2
3
4
5
6
library(scatterplot3d)
fig <- scatterplot3d(
x=rfm$recency, y=rfm$frequency, z=rfm$monetary, color=rfm$color,
xlab='R', ylab='F', zlab='M',
angle=45, mar=c(3,3,3,3), pch=22
)
四、分析报告
分析报告是分析结果的最终呈现,决定了数据分析项目的最终价值。报告的一般思路为:以关键分析问题为主题,确定对应结论;以问题的拆解思路为框架,组织结论的阐述。 在此主题框架的基础上,通过具有明确逻辑的图、表、叙述,来阐述数据分析的结论。最后做出在业务上的指导。同时需要注意几个关键问题:逻辑的说服力、图表的洞察力,以及决策指导的有效性。
在本例中由于数据的限制,未能以完整的框架阐述分析结果,仅叙述部分重要结论。以关键分析问题在业务流程中的拆解为思路,主要探讨如何在商品销售过程中提高平台的销售业绩,得出的主要结论包括以下方面。
4.1 营销策略
(1)提高热门商品的点击率和购买转化率
下图将热门商品类别以及具体商品按点击量降序排列,并计算了相应的购买数量和购买转化率。其中,热度最高的类别(ID:4756105)在 9 天内总点击量接近 5 万,但是购买转化率只有 0.6% ;转化率较高的商品类别(ID:1464116)点击量只有 3~4 千。而热度最高的商品转化率只有 0.4%;很多转化率很高的商品根本没有选上热门。
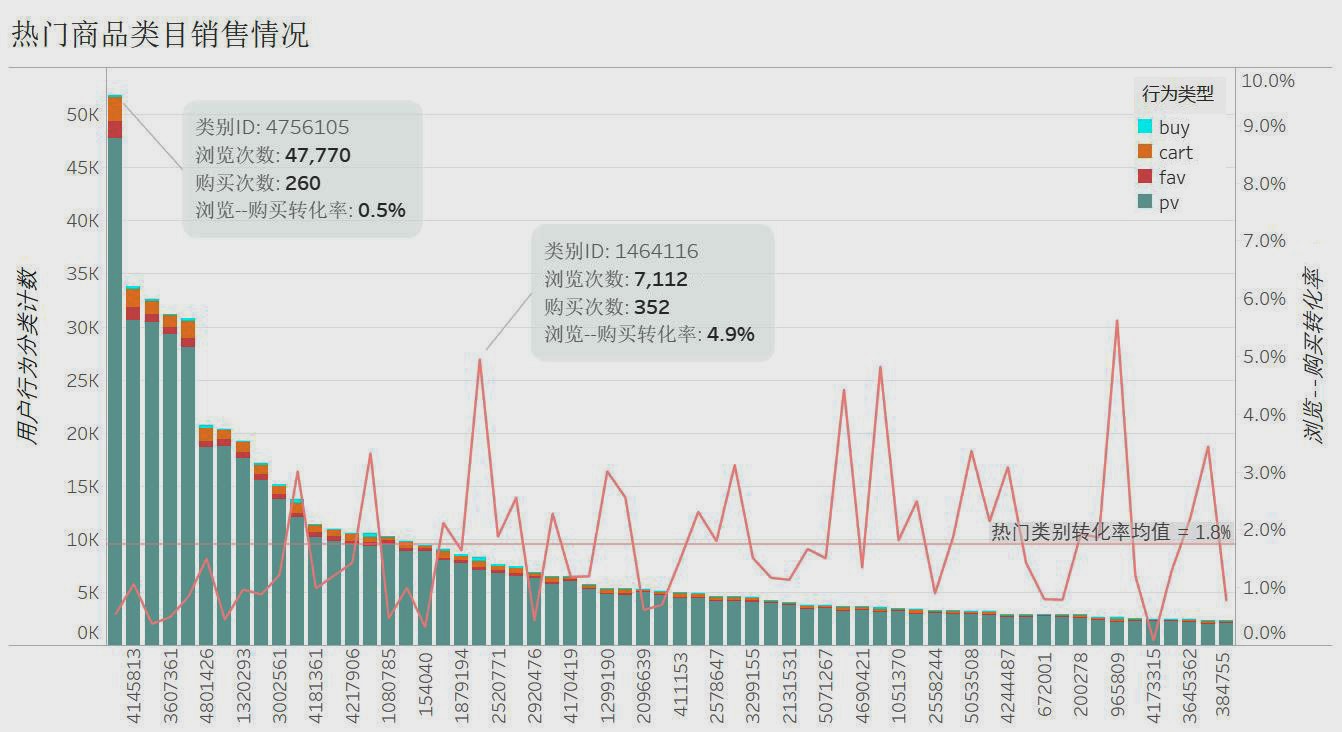
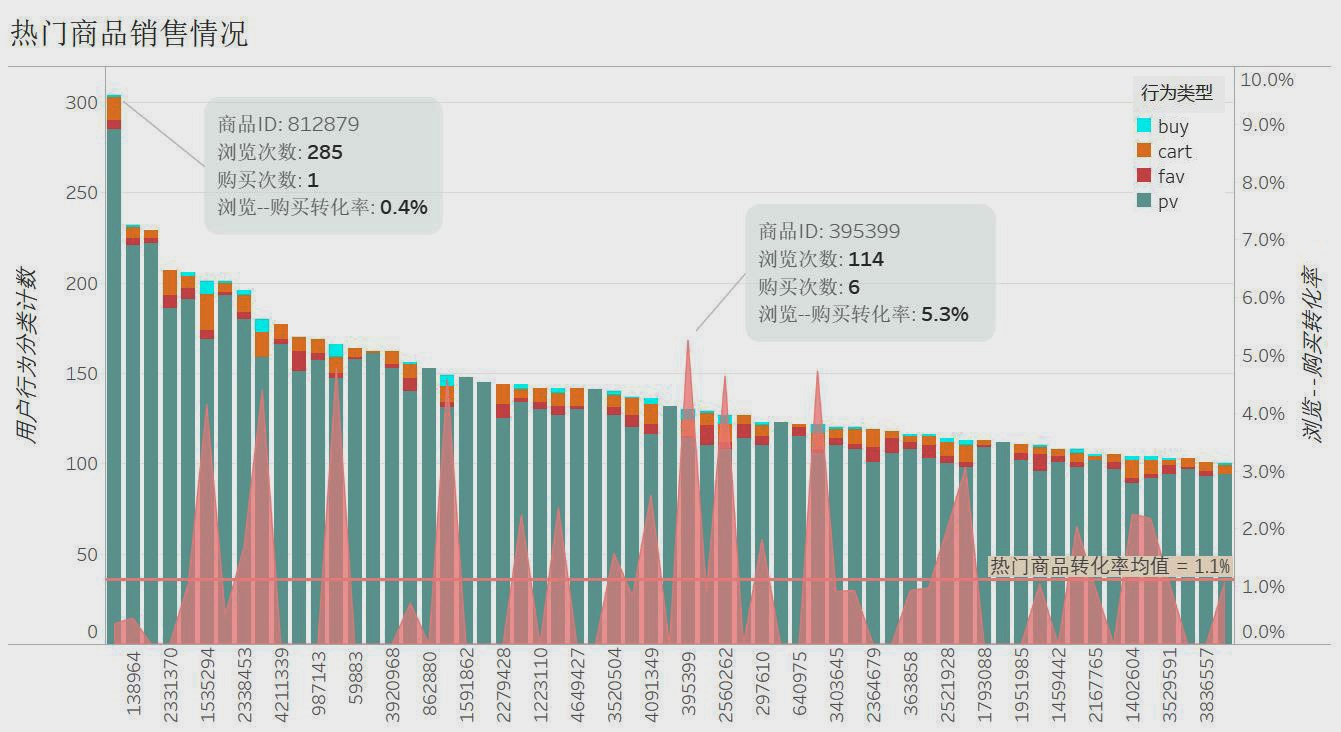
总的来说,热门商品的购买转化率普遍不高。因此,一方面应该通过更多的推荐以及搜索匹配,以及针对用户群体精准推送,提高转化率高的商品的点击量;另一方面,对于一些关注度较高但是转化率低的商品以及商品类别,从各方面提高内容质量以激起用户购买欲望。
(2)充分发掘用户价值
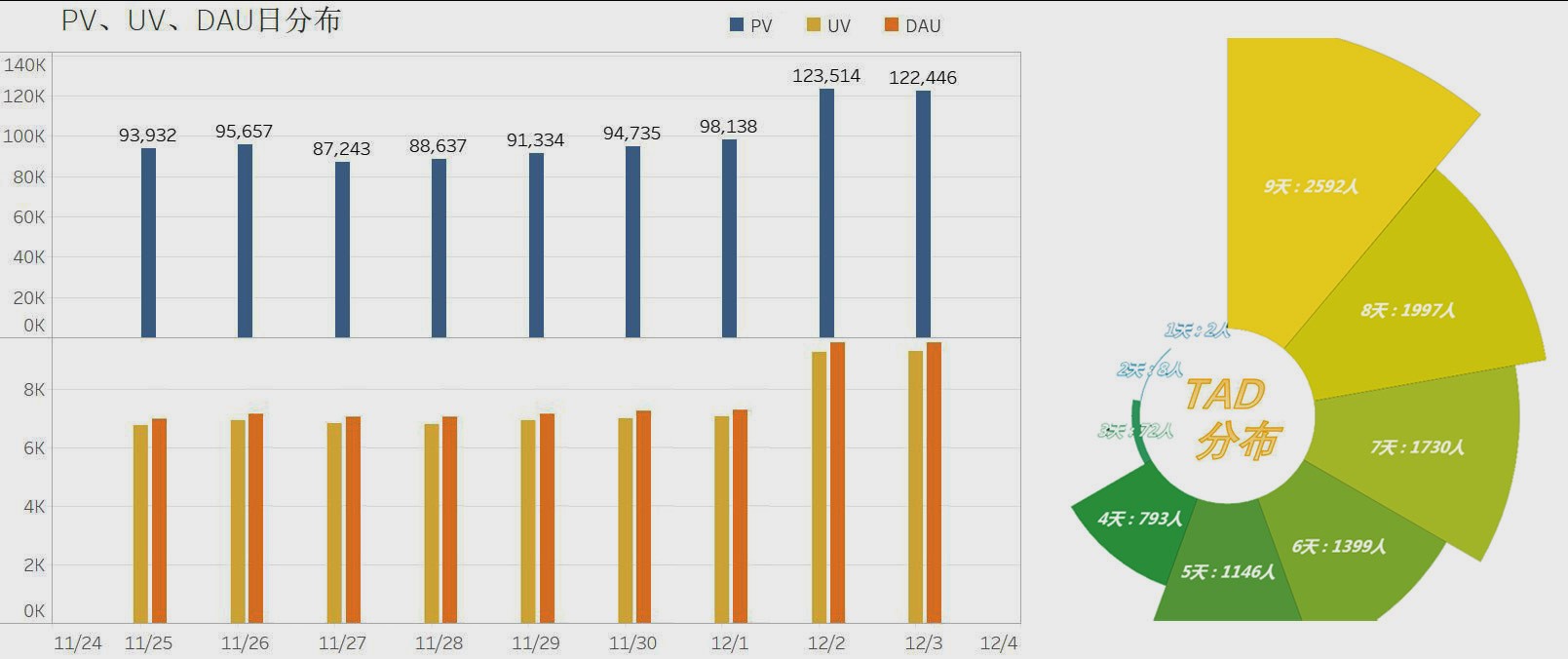
首先看一下用户的活跃情况,通过页面浏览量、独立访客数和日活量,可以看到用户活跃程度较高。并且在 12-02 日用户活跃度有较明显的跳跃。通过用户 TAD 分布可以看到,在所选数据范围中,每天都活跃的用户占约 25%。用户活跃度指标表现优秀,可以使用归因查找方法确定 12-02 日访客增加的原因,利用相关策略进一步提高用户活跃度。
再来看一下用户新增和留存情况,注意到这里的新增和留存都是相对于“购买”行为而言的。由于数据源时间跨度较短,前几天的新增用户数有虚高情况。通过从新增日期开始,到 12-03 的每日日留存计算平均日留存,结果稳定在 20% 左右。可以粗略理解为:每五位新增购买用户中,有一位会在一周内的某一天或多天进行再次购买。通过计算得到 9 天中所有购买用户的复购率为 66.2%,平均每付费用户 3 次购买。
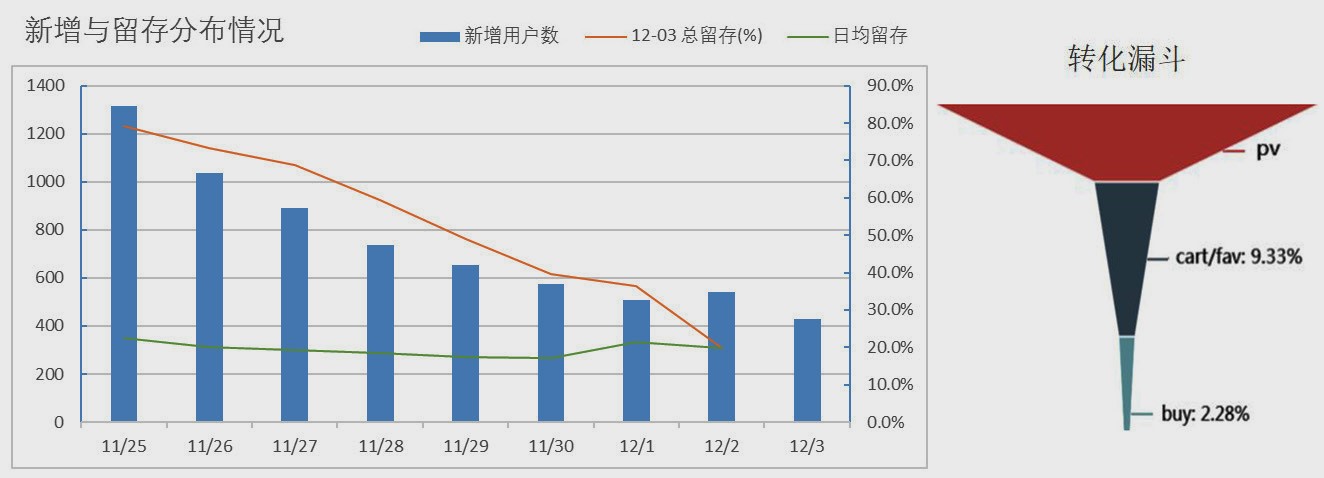
总得来说,用户活跃程度高,平均用户价值也较高。而购买转化率还有一定提升空间。从转化漏斗可以看到,总体的购买转化率只有 2.28%,没有充分利用活跃用户的价值。因此可以通过更多的优惠促销活动,抓紧消费者心理,提高新增、留存和转化率指标,发掘用户更大的价值。
4.2 用户策略
从前面分析可以看到,不同的用户活跃度与价值质量有一定差异。例如,9 天内平均每付费用户 3 次购买,较为可观;而所有活跃用户的购买转化率为 2.28%,仍有提升空间。因此可以挖掘用户的行为模式,以及计算不同用户的价值,通过有针对性的用户策略,提升总体业绩指标。
(1)精准化营销
下面从用户的行为模式对用户的分群。下图显示了用户在不同行为类型构成的三维空间中的分布,并根据行为特征对用户进行了分类。右上图例显示了每一个聚类的中心的位置,右下图例显示了不同类别的数量分布。
图中,每类用户具有差异化的行为特征。例如,浅蓝色类别的用户属于活跃度中等,但是购买数量较多的用户,属于转化率较高的群体。从数量分布可以看到,只有极少用户满足该类特征。因此应该重点提高该类用户的数量以及活跃程度。红色类别的用户属于活跃程度高,而购买力一般的用户,可通过更多的优惠刺激以及精准推荐,增加该类用户购买行为。而绿色用户属于价值一般的群体,应该重点发展和保留。
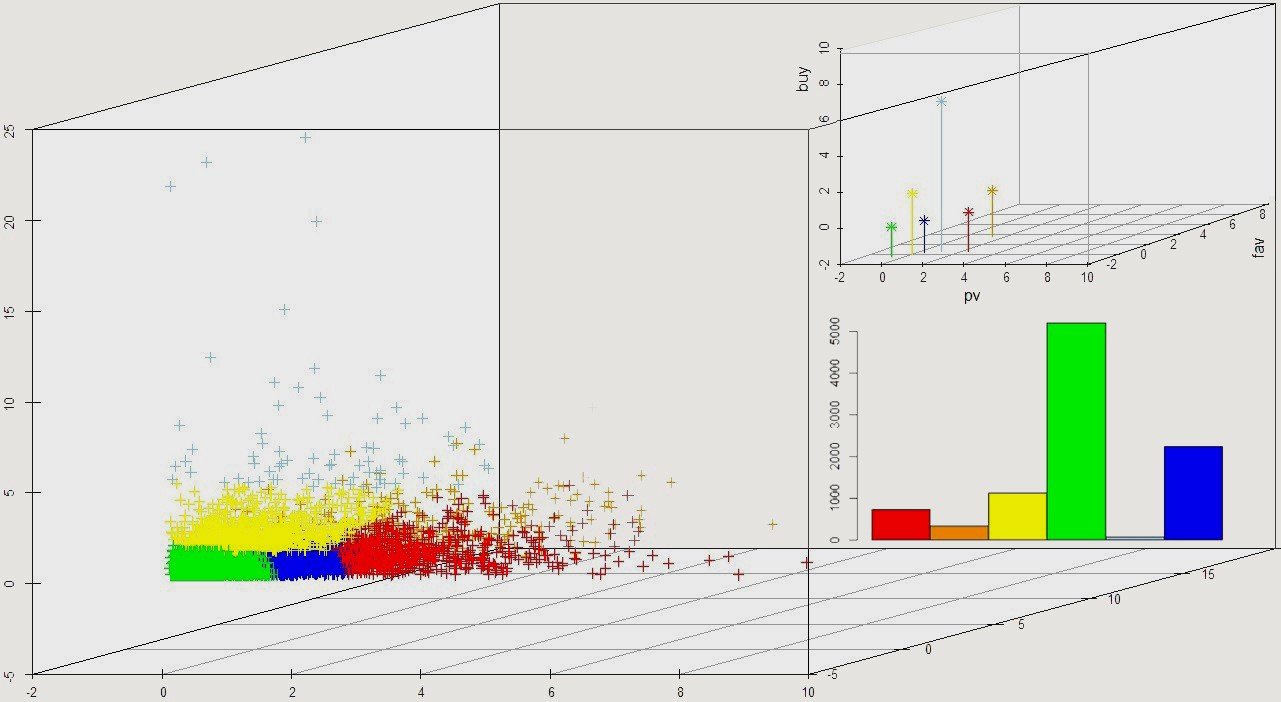
这里由于数据有限,只从少量维度刻画用户的特征。可以引入更多的用户特征变量,形成更细致的用户画像,并对不同群体实施更精准的营销。
(2)培养高价值用户
下面根据 RFM 模型计算不同用户的价值。这里由于数据有限,用平均购买行为时间间隔表示 Frequency,用购买次数表示 Monetary。下面四个图分别显示了 RFM 三个维度的用户数量分布以及最后的分类结果。
从分布图可以看到,最近一次购买时间分布集中在初始日期附近,大部分用户的购买频率集中在 1~2 天一次,近 6 成用户购买次数为 1~2 次。
最后的图中以中位数为界,从三个维度将用户划分为 8 群。其中红色类别(AAA)为高价值用户群体,可综合该类用户的特征,培养更多高价值用户。橙色类别(BAA) Recency 评分偏低,可通过更多促销活动培养用户习惯。 蓝色类别(BBB)的用户三个维度的评分均偏低,应重点发展避免流失风险。
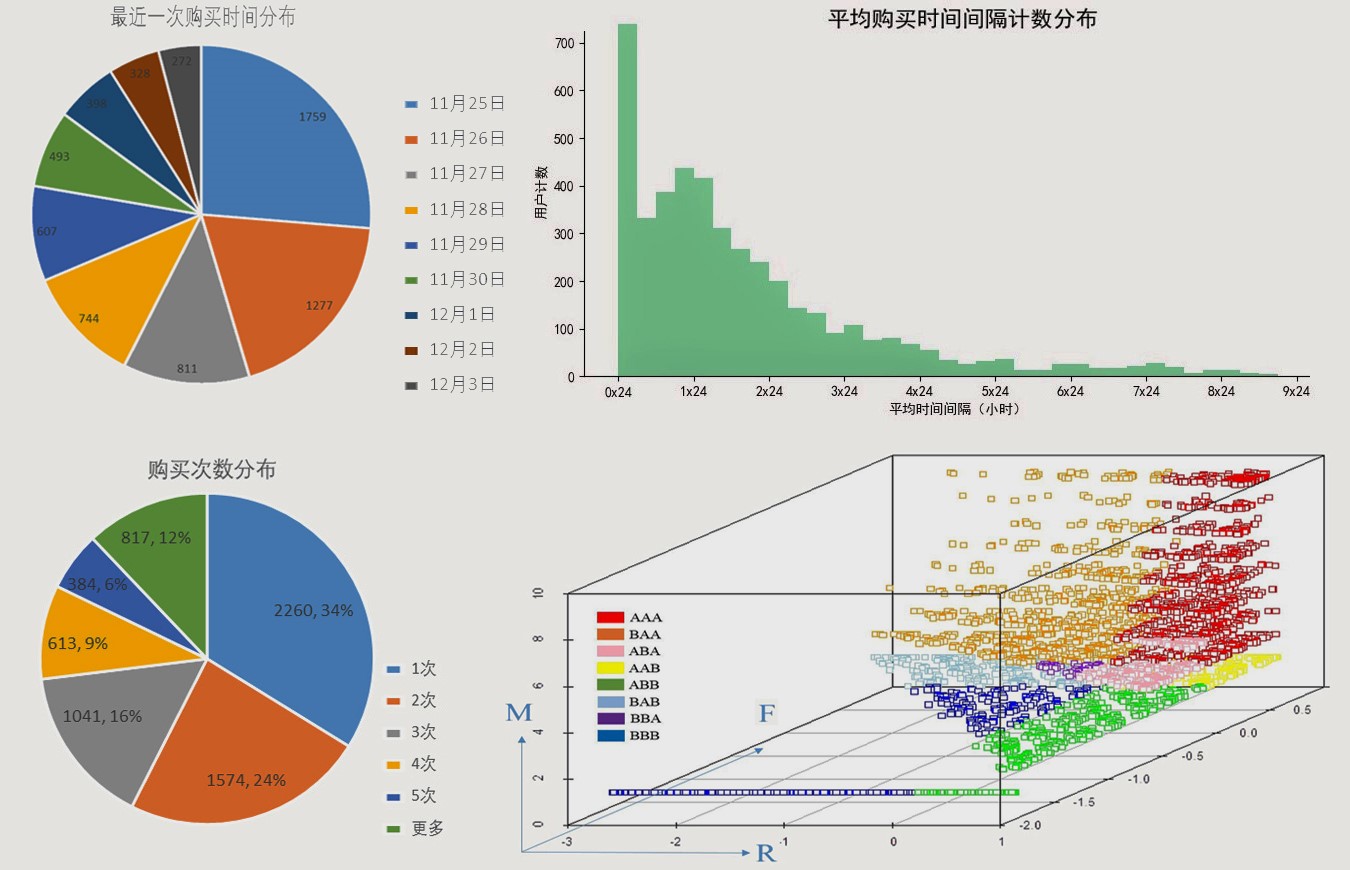
以上为一个粗略的评估。在长期数据的支持下,结合客单价数据,可以更精确地评估客户价值,并培养更多高价值用户,提高销售业绩。