网页视频弹幕获取
平时逛博客经常看到有关视频弹幕的数据分析文章,可以看到从一些热门视频的弹幕和评论数据中可以分析出一些有意思的结论。于是来研究一下获取网站视频弹幕数据的一般方法。可以参考此前的爬虫基础知识总结:
一、浏览器调试模式获取 API
以 Bilibili 为例,首先打开一个视频。这里随便在首页找一个比较热门的视频:
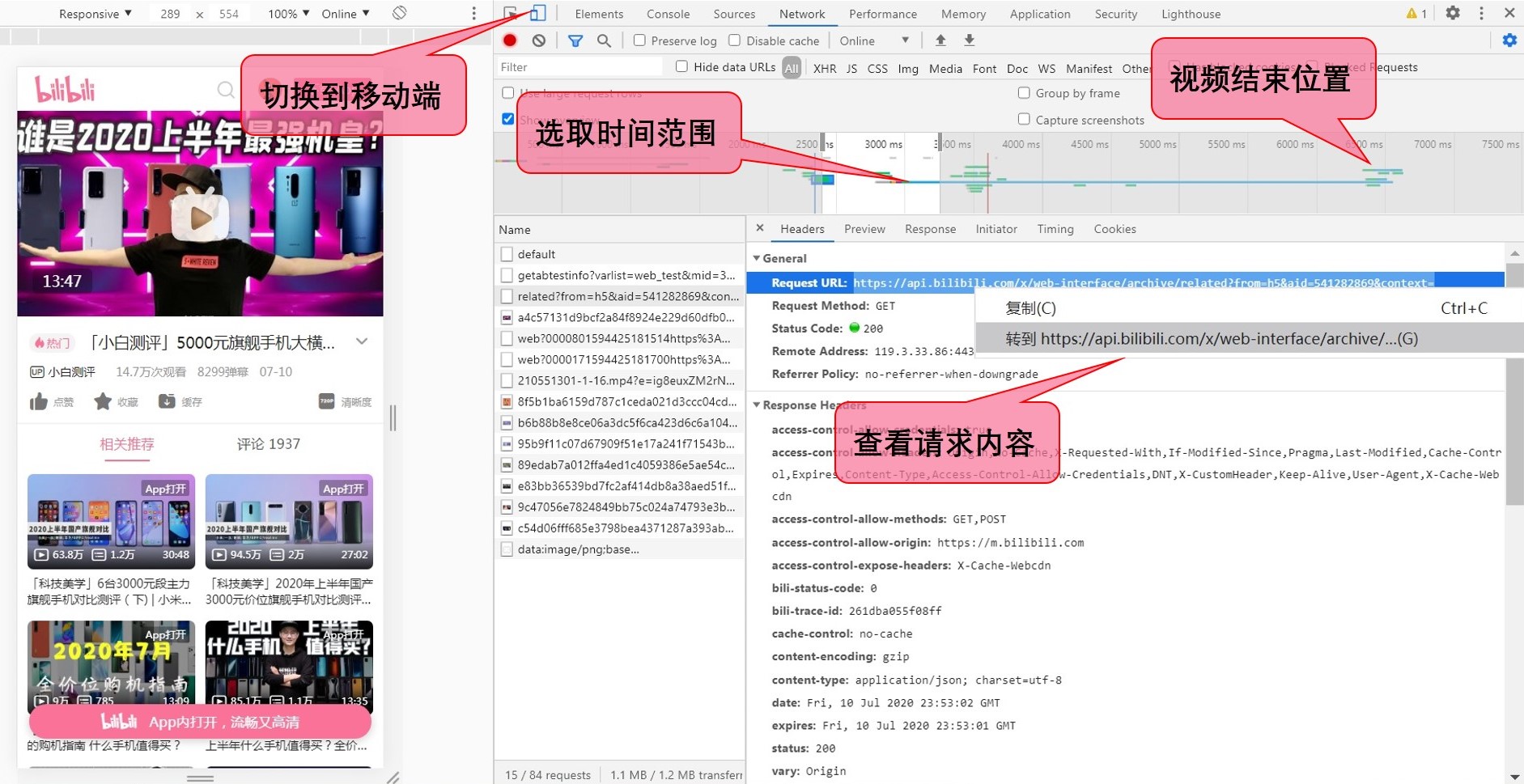
打开视频页面,F12 进入打开调试工具,然后切换到移动端,并刷新网页。这时就可以看到网址由 www.bilibili.com 变成 m.bilibili.com。等待网页加载完成后,在调试工具 Network 选项中就可以看到具体有哪些请求。下一步需要锁定获取弹幕数据的请求。
由于请求的数量非常多,需要缩小范围。这里盲猜弹幕数据是在视频的前后开始请求的,而下图中那一长条蓝色的部分应该就是视频数据流。可以选中它查看它的具体信息,在新标签中打开请求链接,发现的确是视频的直链。然后再在框选的范围中一个个查看请求的内容,这里没有找到弹幕的请求链接,只有一个相关视频的信息,名字为 related?from=h5&aid= ...。然后再尝试在视频流结束位置的前后来寻找,最后确定名为 list.so?oid=210551301 的请求返回的就是弹幕数据。
这里理论来说可以一个个请求去查看,最终找到弹幕的 API。也可以发挥想象力用各种方法缩小搜索范围。
二、使用脚本请求数据
事实上打开链接后,直接 Ctrl S 数据就到手了,但是可能需要获取多个相关视频、或者 Up 主的一系列视频的弹幕数据,这里需要用脚本请求。从 API 链接可以看到,它的 oid 参数跟视频链接的序号是不一样的。因此首先从视频链接获取对应的 oid。直接 GET 请求视频链接,返回的信息中就包含 oid 参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import re
import requests as rq
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'}
def get_param(link):
'''由视频链接获取 id 参数'''
res = rq.get(link, headers=headers)
reg = "var options = {.*?aid: (.*?),.*?bvid: '(.*?)',.*?cid: (.*?),.*?}"
ids = re.compile(reg, re.S).findall(res.text)[0]
params = dict(zip(['aid', 'bvid', 'cid'], ids))
if params['bvid'] == link.split('?')[0].split('/')[-1]:
return params
else:
print('Extraction Error!')
return 0
接下来通过视频对应的 id 构造链接请求弹幕数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from bs4 import BeautifulSoup
def get_dm(id, write=False):
'''id 对应 get_param 函数返回的 cid 字段'''
url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={id}'
res = rq.get(url, headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'xml')
dms = [d.text for d in soup.find_all('d')]
if write:
with open(f'{id}.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(dms))
print(f'\n已写出文件 {id}.txt\n')
else:
return dms
最后获取另外一个视频的弹幕测试一下:
1
2
url = 'https://www.bilibili.com/video/BV1mK4y1479e'
get_dm(get_param(url)['cid'], True)
三、其他视频网站
B 站只是一个“小破站”,没多少挑战性,下面试一下“大站”看看有什么不同。
Two Thousands Years Later …
广告好长,全是 VIP 视频,算了有空再搞。。。