MAE(Mean Absolute Error)
顾名思义,即“绝对误差的均值”:
使用 MAE 指标的优点是,计算出的误差指标的量纲与目标变量一致,并且对离群值不敏感。缺点则是由于其函数不可微,不能作为损失函数,因此在不能作为优化器。如果需要最小化 MAE 来拟合回归模型,需要引入其他优化器,如梯度下降。
MSE(Mean Squared Error)
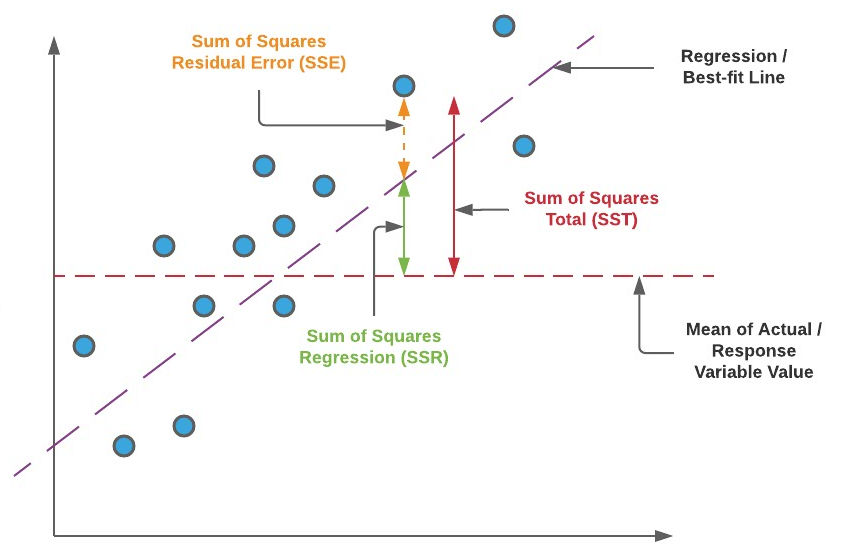
顾名思义,即“平方误差的均值”,在这里顺便了解一下 SSE 的概念:
其优点是,函数可微,可以作为损失函数。实际上最小二乘回归就相当于使用了这个损失函数(最小二乘法通过最小化 SSE 拟合模型)。其缺点是,误差指标的单位变成原始数据单位的平方,并且对异常值敏感。
RMSE(Root Mean Squared Error)
没啥好说,就是上面提到的单位问题,于是就将 MSE 开平方了。
RMSLE(Root Mean Squared Log Error)
RMSE 存在的问题是,对偏小的预测值惩罚较大,也就是对于不同的误差惩罚不是线性的,因此再取对数,来减小这个问题的影响(实际上没有解决问题)。
R2(R Squared)
R2 又称为拟合优度或确定系数,前面 MSE 已经提到 SSE,这里顺便再提一下 SSR 和 SST:
可以理解为:SSR 为回归方差,SST 为总方差。在统计学中,变异量(即方差)体现了一个随机变量的解释性。因此 R2 的大小体现了预测值对数据变异的解释占总变异的比例,亦即回归模型的好坏。
那么按照这个说法,没有被解释到的去哪里了呢?就在误差 SSE 里面了:
Adjusted R2
R2 的缺点是,它只会升不会降。也就是说,你可以在模型中不断添加新的特征,来提高拟合优度(至少不会降低),即使这些新特征是线性不相关的。因此使用 R2 来对比两个具有不同特征数量的模型是不准确的,只试用于单个模型的拟合优度。针对 R2 的这个问题,通过以下式子引入样本量和自由度来进行调整:
其中 n 为样本数,k 为独立变量个数。