request selenium re bs4 pymysql sqlalchemy pandas_profiling
一、数据获取
(1)网页分析
https://list.jd.com/list.html?cat=9987,653,655
在商品展示页,通过 requests 请求返回的数据隐藏了价格信息,尝试在 headers 中加入 cookies 但是没有作用。由于数量不大,可以使用 selenium 自动化获取。通过遍历 URL 中的 page 字段可以获取到所有的商品ID,通过商品ID进入详情页可以获取商品的具体信息:
https://item.jd.com/100000287117.html
留意到详情页中可以选择不同的商品型号,展示不同的信息。为了减少数据复杂程度,只采集默认的商品型号的信息。
(2)获取展示页信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# ...
# 获取商品展示页信息
def get_info(driver):
'''返回单页的商品ID、价格、标题、评论数量、店铺名称'''
# ...
xpath = '//*[@id="plist"]/ul/li[{}]/div'
for i in range(1,61):
# 获取 outerHTML
element = driver.find_element_by_xpath(xpath.format(i))
html = element.get_attribute('outerHTML')
# 解析相应字段内容
id = re.compile(r'data-sku="(.*?)"').findall(html)[0]
price = driver.find_element_by_xpath(
'//*[@id="plist"]/ul/li[{}]/div/div[3]'.format(i)
).text[1:]
# ...
# 解析以及保存信息
for name in ['id', 'price', 'title', 'comment', 'shop']:
exec(f'{name}_list.append({name})')
return [id_list, price_list, title_list, comment_list, shop_list]
if __name__ == '__main__':
# 以无图浏览模式创建 Chrome 实例,可以大幅度节省时间
options = webdriver.ChromeOptions()
options.add_experimental_option(
'prefs', {'profile.managed_default_content_settings.images': 2}
)
driver = webdriver.Chrome(chrome_options=options)
# 每页信息单独写入 csv 文件,如果中途出错可以进行“断点续传”
URL = 'https://list.jd.com/list.html?cat=9987,653,655'
URL += '&page={}&stock=0&sort=sort_rank_asc&trans=1&JL=4_7_0'
for i in range(page_num):
driver.get(URL.format(i+1))
data = get_info(driver)
# 写入csv文件
pd.DataFrame(np.array(data).T).to_csv(f'第{i+1}页.csv')
driver.close()
# 合并所有表格并写出
# ...
df.to_csv('displace.csv', index=None)
(3)获取商品详情
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# ...
def get_params(html):
'''返回字典,包含重点参数的各个字段以及所有参数组成的文本信息的一个字段'''
# 获取ul标签的所有li标签
regex = r'<ul class="parameter2 p-parameter-list">(.*?)</ul>'
lis = BeautifulSoup(re.compile(regex).findall(html.replace('\n', ''))[0],
'html.parser').find_all('li')
# 重点参数(比较整齐,可以直接解析成字典)
params = dict([li.text.replace(' ', '').split(':')[:2] for li in lis])
# 增加品牌字段
brand = BeautifulSoup(
html.replace('\n', ''), 'html.parser'
).find_all(
'ul', attrs={'id': 'parameter-brand'}
)[0].text.replace(' ', '').split(':')
params[brand[0]] = brand[1]
# 包含所有参数的文本
regex = r'<div class="Ptable-item">(.*?)<div class="package-list">'
dls = BeautifulSoup(
re.compile(regex).findall(html.replace('\n' ,'|'))[0], 'html.parser'
).find_all('dl', attrs={'class': 'clearfix'})
params['all_params_raw_text'] = '||'.join(
[dl.text.replace(' ', '') for dl in dls])
return params
if __name__ == '__main__':
# ...
for i in range(len(id_list)):
try:
html = rq.get(URL.format(id_list[i]), headers=headers).text
params_list.append(get_params(html))
except Exception as e:
print(e)
Beep(2000, 1000)
pd.DataFrame(params_list).to_csv('details.csv', index=None)
二、数据清洗
(1)合并总表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# ...
# 合并展示页和详情页获取的信息
all_data = displace.merge(details, on='商品编号', how='outer')
# 解析 all_param_raw_text 中的字段
name_list = {
'品牌': (lambda t: re.compile(r'\n品牌(.*?)\n').findall(t)),
'产品名称': (lambda t: re.compile(r'产品名称(.*?)\n').findall(t)),
'上市年月': (lambda t: [[re.compile(r'上市年份(.*?)年').findall(t),
re.compile(r'上市月份(.*?)月').findall(t)]]),
# ...
}
# 使用商品编号作为“主键”,将解析结果储存到 df
df = pd.DataFrameall_data['商品编号'])
for name, func in name_list.items():
all_data['all_params_raw_text']]
all_data.drop('all_params_raw_text', axis=1, inplace=True)
# 用 all_data 对 df 中重复字段进行补值
name_list = ['品牌', '产品名称', '机身颜色', 'CPU型号', '屏幕尺寸(inch)',
'后置主摄像素(万)', '前置主摄像素(万)', '电池容量(mAh)']
for name in name_list:
df[name] = [t1 if t1 else t2 for (t1, t2) in zip(df[name], all_data[name])]
# 丢弃已用于填充的字段
all_data.drop(name_list, axis=1, inplace=True)
# 合并
merge_df = df.merge(all_data, on='商品编号', how='outer')
(2)清洗总表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 由于对于不同的模型算法,对数据有不同清洗需求,不能一概而论
# 使用以下函数进行初步的数据清洗,保留大部分信息。
def check_field(name, df):
'''检查 name 字段取值是否包含异常值'''
return list(df[name].value_counts().index)
def replace_values(name, to_value, value_list, df):
'''将 name 字段中包含在 value_list 的取值替代为 to_value'''
df[name] = [to_value if t in value_list else t for t in df[name]]
return df
def replace_str(name, to_str, str_list, df):
'''将 name 字段的每个值中包含在 str_list 的字符替代为 to_str'''
for s in str_list:
df[name] = [t.replace(s, to_str) if t else None for t in df[name]]
return df
def parse_numeric(name, leng, ulimit, llimit, df):
'''将字符串解析为数值型数据。leng控制有效值长度;ulimit、llimit过滤异常值。'''
df[name] = ['.'.join(re.compile(r'\d+').findall(str(t))) for t in df[name]]
df[name] = [t[:leng] if len(re.compile(r'\.').findall(t))>1 else t \
for t in df[name]]
df[name] = [None if t == '' else float(t) for t in df[name]]
df[name] = [None if t<llimit or t>ulimit else t for t in df[name]]
return df
def drop_duplicated(df, key):
'''去除重复的观测'''
value_set = []; ilist = []
for i in range(len(df)):
if df[key][i] in value_set:
ilist.append(i)
value_set.append(df[key][i])
return df.drop(ilist)
三、数据存储
1
2
3
4
5
6
7
8
9
CREATE TABLE IF NOT EXISTS jd_phones(
`商品编号` BIGINT(20) NOT NULL,
`品牌` VARCHAR(20),
`价格` FLOAT(10,3),
`商品标题` TEXT(511),
`评论热度` INT(20),
-- ...
PRIMARY KEY (`商品编号`)
)
1
2
3
4
engine = sqlalchemy.create_engine(
f'mysql+pymysql://{usr}:{pw}@localhost:3306/{db}?charset=utf8'
)
tidy_df.to_sql('jd_phones', con=engine, if_exists='append', index=False)
四、描述性统计分析
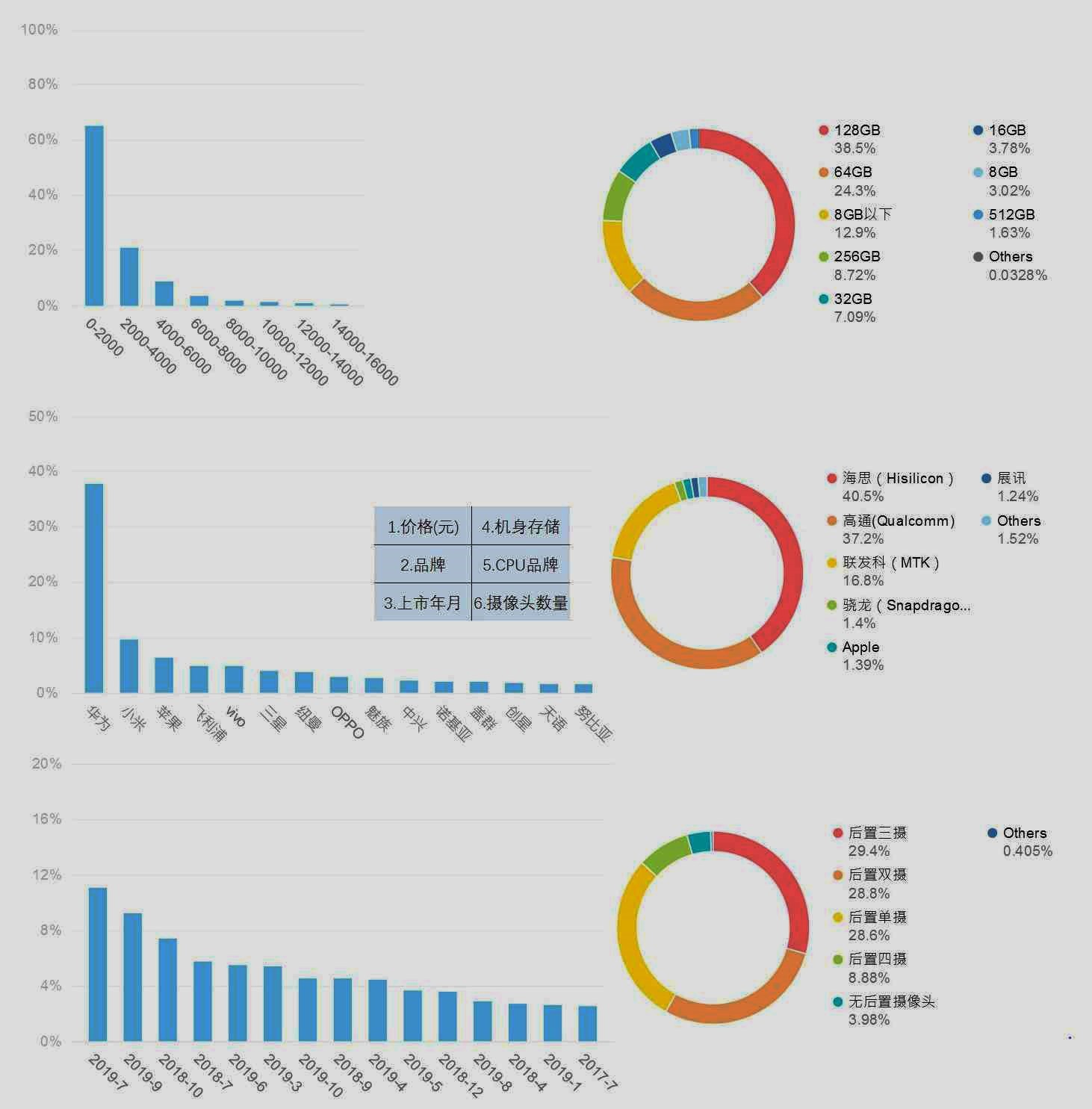
(1)重点字段预览
(2)详细统计报告
统计分析报告 | 新标签页查看