一、数据源
来自某医药公司的产品销售数据,时间为 3 月到 5 月,共 48 个 Excel 表格。包含订单信息、售后信息、用户信息以及对应销售人员信息等。

加载合并后得到的原始数据如下:

二、数据清洗
清洗流程以及对应细节
- 加载数据源
- 表格形式没有统一,需要手动根据列名找到表头所在行
- 文件名包含日期信息,提取并加入到 DataFrame 新列
- 纵向拼接所有文件产生的 DataFrame
- 部分表格列名缺失,被加载到
Unnamed: 0列,手动合并回对应列- 数据清洗
- 检查每列的唯一值和频数分布
- 删除含有无用信息的列和含有过多缺失、无效值的列
- 拆分下单日期和下单时间
- 信息脱敏
- 将详细的收货地址映射为省份
- 员工名称用代号表示
- 商品名称用代号表示
- 输出员工名称和商品名称的映射字典以便回溯
- 使用 pandas_profiling 输出汇总报告
展开查看数据预处理代码 ▼ ▼ ▼
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
# 读取
def read_table(name):
# 表格形式没有统一,需要找到表头所在行
for i in [2,1,0,3,4,5,6,7,8,9]:
df = pd.read_excel(name, header=i)
cols = list(df.columns)
# 部分表格列名不全,用两个字段确保匹配
if '回访人' in cols or '订单编号' in cols:
break
# 从文件名中提取日期,加入新列
m, d = re.findall(r'(\d*?\.\d*?)日', name)[0].split('.')
if int(d) < 10:
d = '0' + d
df['回访日期'] = f'2023-0{m}-{d}'
return df
# 合并
def join_table(files):
source_df = pd.DataFrame()
for f in files:
df = read_table(f)
source_df = source_df.append(df).reset_index().drop('index', axis=1)
print(f'【读取成功】{f}')
return source_df
os.chdir('source_df')
source_df = join_table(os.listdir())
os.chdir('../')
# 部分表格没有回访人这个列名,被自动归到了新列,现在合并
source_df['回访人'].fillna(source_df['Unnamed: 0'], inplace=True)
# 删除失效的列和含有空值的行
source_df.drop(['Unnamed: 0', 'Unnamed: 20'], axis=1, inplace=True)
source_df.dropna(axis=0, how='any', inplace=True)
# 删除含有隐私信息和无用信息的列
dumps = [
'客户姓名', '签收日期', '坐席人员', '订单编号', '发货编号', '快递编号', '商家备注',
'收货人号码', '来电号码', '购买用途', '客户微信', '店铺名称', '出生日期', '业务类型'
'是否为**用户', '是否添加微信', '销售状态', '收货人姓名', '来电日期', '客户情况备注'
]
df = source_df.drop(dumps, axis=1)
# 拆分下单日期
orderdate = df['下单日期'].str.split(' ')
df['下单日期'] = [r[0] for r in orderdate]
df['下单时间'] = [r[1].split(':')[0] for r in orderdate]
# 重新映射地址
def mapaddress(address):
provinces = [
'上海市', '广东省', '浙江省', '四川省', '河南省', '江苏省', '北京市', '湖北省', '海南省',
'广西壮族自治区', '山东省', '安徽省', '陕西省', '福建省', '甘肃省', '湖南省', '江西省',
'辽宁省', '云南省', '天津市', '重庆市', '山西省', '内蒙古自治区', '贵州省', '吉林省',
'黑龙江省', '宁夏回族自治区', '青海省', '河北省', '新疆维吾尔自治区', '西藏自治区'
]
for province in provinces:
if province in address:
return province
df['客户地址'] = [mapaddress(ad) for ad in df['客户地址']]
df = df[-df['客户地址'].isna()]
# 信息脱敏
staffs = list(df['回访人'].value_counts().index)
staff_mapping = dict(zip(staffs, ["staff_" + chr(i+65) for i in range(len(staffs))]))
df['回访人'] = df['回访人'].map(staff_mapping)
products = list(df['商品名称'].value_counts().head(9).index)
product_mapping = dict(zip(products, ["product_" + chr(i+65) for i in range(len(products))]))
df['商品名称'] = df['商品名称'].map(product_mapping)
df['商品名称'] = df['商品名称'].fillna('others[262]') # 另有 262 种不同商品或商品组合
# 保存数据映射
with open('staffs.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(staff_mapping, ensure_ascii=False))
with open('products.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(product_mapping, ensure_ascii=False))
# 数据概览
profile = ProfileReport(df, minimal=True, explorative=False, dark_mode=True)
profile.to_file('dataset-report.html')
df.to_csv('data.csv', index=None)
数据概览报告
三、业务分析
提取数据中含有的信息提供对业务情况的洞察:
- 不同地区的销售情况对比,作为业务优化参考
- 下单时间分布,揭示用户行为习惯
- 单日订单量异常检测,追溯业务中可能存在的问题
- 员工销售情况分析,提高销售效率
- 来源渠道分布和 SKU 销量分布,及其关联分析
展开查看可视化分析代码 ▼ ▼ ▼
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from scipy import stats
from Heaven import mpl_tools # https://github.com/paradiseeee/heaven
setting = mpl_tools.Begin()
setting.set_font_family()
setting.set_axis_unicode()
setting.set_style('dark_background')
import pyecharts
import pyecharts.charts as pyc
import pyecharts.options as opts
import pyecharts.globals as glbs
from pyecharts.commons.utils import JsCode
def render(filename, chart):
'''更改 js 引用源以提高加载速度'''
chart.render(filename)
js_0= 'https://cdn.jsdelivr.net/npm/echarts@latest/dist/'
js_1 = 'https://assets.pyecharts.org/assets/'
with open(filename, 'r', encoding='utf-8') as f:
html = f.read().replace(js_0, js_1)
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
def packing(series):
'''将序列打包为 pyecharts 接收的 data_pair'''
res = list(
zip(
series.index,
zip(
[int(i) for i in series],
[round(i, 2) for i in scale(series)]
)
)
)
return res
from sklearn.preprocessing import MinMaxScaler
def scale(series):
'''pd.series 转换维度归一化并转移为一维列表'''
arr_T = np.array(series).reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(arr_T)
return scaler.transform(arr_T).flatten()
# 数据预处理后生成的数据
df = pd.read_csv('data.csv')
print(df.info())
# 一、地区销售情况对比
# 省份列表
provinces = [
'上海市', '广东省', '浙江省', '四川省', '河南省', '江苏省', '北京市', '湖北省',
'广西壮族自治区', '山东省', '安徽省', '陕西省', '福建省', '甘肃省', '湖南省', '江西省',
'辽宁省', '云南省', '天津市', '重庆市', '山西省', '内蒙古自治区', '贵州省', '吉林省',
'黑龙江省', '宁夏回族自治区', '青海省', '海南省', '河北省', '新疆维吾尔自治区', '西藏自治区'
]
# 数据准备
orderNums = df['客户地址'].value_counts() # 地区订单量分布
totalSales = df.groupby('客户地址')['订单金额'].sum() # 地区订单总金额分布
meanSales = df.groupby('客户地址')['订单金额'].mean() # 地区订单均值分布
# 绘图
map = pyc.Map(
init_opts=opts.InitOpts(theme=glbs.ThemeType.DARK, width='100%', height='400px', bg_color='#1a1c1d')
).add(
series_name='总销售额',
maptype='china',
is_map_symbol_show=False,
zoom=1.24,
data_pair=packing(totalSales),
emphasis_itemstyle_opts=opts.ItemStyleOpts(area_color='#AABB33')
).add(
series_name='订单数量',
maptype='china',
is_map_symbol_show=False,
zoom=1.24,
data_pair=packing(orderNums),
emphasis_itemstyle_opts=opts.ItemStyleOpts(area_color='#AABB33')
).add(
series_name='均销售额',
maptype='china',
is_map_symbol_show=False,
zoom=1.24,
data_pair=packing(meanSales),
emphasis_itemstyle_opts=opts.ItemStyleOpts(area_color='#AABB33')
).set_series_opts(
label_opts=opts.LabelOpts(color='#889099', is_show=False)
).set_global_opts(
title_opts=opts.TitleOpts(title="地区销售情况对比"),
legend_opts=opts.LegendOpts(
# orient='vertical',
selected_mode='single',
pos_left='2%', pos_bottom='2.5%',
item_gap=6, item_width=25, item_height=16
),
visualmap_opts=opts.VisualMapOpts(
min_=0, max_=1,
precision=2,
range_color=["#78A8F4", "#3F44A8", "#AD0083"],
range_text=["100 %", "0 %"],
is_calculable=True,
orient='horizontal', pos_left='right', pos_top='90%',
item_width=12, item_height=100
)
)
# 渲染
render('地区销售情况对比.html', map)
# 输出数据备份
sales = pd.DataFrame({'address': list(orderNums.index)})
sales['orderNums'] = sales.address.map(dict(orderNums))
sales['totalSales'] = sales.address.map(dict(totalSales))
sales['meanSales'] = sales.address.map(dict(meanSales))
sales.to_csv('sales-by-provinces.csv', index=None)
# 二、下单时间分布饼状图
# 类似时钟的饼状图,宽度相等,通过颜色代表数值大小
clock = pd.DataFrame(zip(range(24), [1]*24, [0]*24), columns=['hour', 'width', 'value'])
clock.value = clock.hour.map(dict(df['下单时间'].value_counts())).fillna(0)
def plot_pie(clock=clock, meridiem='AM/PM'):
clock = clock[:12] if (meridiem == 'AM') else clock[12:]
pie = pyc.Pie(
init_opts=opts.InitOpts(theme=glbs.ThemeType.DARK, width='100%', height='360px', bg_color='#1a1c1d')
).add(
series_name = '时间分布',
data_pair = list(zip(clock.hour, zip(clock.width, clock.value)))
).set_series_opts(
label_opts=opts.LabelOpts(position='inside'),
tooltip_opts=opts.TooltipOpts(
formatter=JsCode( # 默认工具提示显示宽度大小数值,需要手动设置
'''
function (data) {
var start = data.name;
var end = parseInt(data.name) + 1;
var pop = parseInt(data.value[1]);
var line1 = start + ':00 ~ ' + end + ':00 ';
var line2 = '下单人数:' + pop;
return line1 + '<br/>' + line2;
}
'''
)
)
).set_global_opts(
title_opts=opts.TitleOpts(title=f'下单时间分布({meridiem})')
)
# 根据分布数值大小映射颜色
colormapper = plt.get_cmap('YlOrRd', int(max(clock.value))+1)
colorseq = [mpl.colors.to_hex(colormapper(int(v))) for v in clock.value]
pie.options['color'] = colorseq
return pie
# # 自带的 Page 对象很难调整,直接写个 html 嵌入(下单时间分布.html)
# page = pyc.Page(page_title='下单人数时间分布', layout=opts.PageLayoutOpts(display='inline', flex_wrap='nowrap'))
# page.add(plot_pie(meridiem='AM'), plot_pie(meridiem='PM'))
# page.render()
# render('AM.html', plot_pie(meridiem='AM'))
# render('PM.html', plot_pie(meridiem='PM'))
plot_pie(meridiem='AM').render('AM.html')
plot_pie(meridiem='PM').render('PM.html')
# 三、单日订单量异常检测
# 移动窗口平均(周)
window = 7
orderDates = df.groupby('下单日期')['下单日期'].count()
orderDates.index = pd.Series(orderDates.index).map(lambda d: str(d).replace('2023-', ''))
orderDates_wr = orderDates.rolling(window).mean().fillna(orderDates.head(window-1).mean())
resid = orderDates - orderDates_wr
orderDates.plot()
orderDates_wr.plot()
resid.plot(kind='bar')
# plt.xticks(rotation=45)
plt.title('单日订单量移动窗口平均 & 两者残差', loc='left')
plt.show()
# 残差频率密度分布
resid.hist(density=True)
# 对应的正态分布的概率密度曲线
x = np.linspace(-100, 100, 101)
y = stats.norm.pdf(x, loc=np.mean(resid), scale=np.std(resid))
plt.plot(x, y)
plt.grid(False)
plt.title('残差频率密度分布 & 对应的正态分布', loc='left')
plt.show()
# QQ 图
stats.probplot(resid, dist='norm', plot=plt)
plt.show()
# 四、销售人员业绩考核
def grouping(filed):
odnums = df.groupby(filed)['订单金额'].count()
msales = df.groupby(filed)['订单金额'].mean()
tsales = df.groupby(filed)['订单金额'].sum()
return odnums, msales, tsales
filed1 = '回访人'
grouping_1 = grouping(filed1)
plt.bar(x=grouping_1[0].index, height=grouping_1[0])
plt.xticks(rotation=90)
plt.title('员工订单数量', loc='left')
plt.show()
plt.bar(x=grouping_1[2].index, height=grouping_1[2])
plt.xticks(rotation=90)
plt.title('员工总销售额', loc='left')
plt.show()
# 五、各渠道销售聚合分析(类似地区)
filed2 = '客户来源'
grouping_2 = grouping(filed2)
# 总销售额条形图
plt.bar(x=grouping_2[2][1:].index, height=grouping_2[2][1:])
plt.xticks(rotation=90)
plt.title('各客户来源总销售额')
plt.show()
# 订单数量分布
sample = grouping_2[0][1:].sort_values(ascending=False).head(5)
plt.pie(sample, labels=sample.index)
plt.title('客户来源订单量分布', loc='left')
plt.show()
# 六、SKU 聚合分析
filed3 = '商品名称'
grouping_3 = grouping(filed3)
plt.bar(x=grouping_3[2][1:].index, height=grouping_3[2][1:])
plt.xticks(rotation=90)
plt.title('各 SKU 总销售额')
plt.show()
sample = grouping_3[0][1:].sort_values(ascending=False).head(5)
plt.pie(sample, labels=sample.index)
plt.title('SKU 订单量分布', loc='left')
plt.show()
# 七、渠道-SKU 分析
df_pruned = df[df['商品名称'] != 'others[262]'][df['客户来源'] != ' ']
source_top5 = dict(zip(list('FGHIJ'), df_pruned['客户来源'].value_counts().head(5).index))
# 交叉表
for label in list('ABCDE'):
exec(f"t{label} = df_pruned[df_pruned['商品名称'] == 'product_{label}']['客户来源'].value_counts().head(5)")
for label in list('FGHIJ'):
exec(f"t{label} = df_pruned[df_pruned['客户来源'] == source_top5['{label}']]['商品名称'].value_counts().head(5)")
# 子图布局
# axes = mpl_tools.Func().get_subplots('TTTTTTTTTT\nAABBCCDDEE\nAABBCCDDEE\nFFGGHHIIJJ\nFFGGHHIIJJ')
axes = mpl_tools.Func().get_subplots('ABCDE\nFGHIJ')
plt.title('商品各渠道来源分布 & 渠道各商品销量分布', loc='left')
# 子图与表一一对应
for label in list('ABCDEFGHIJ'):
exec(
f"axes['{label}'].pie(t{label}, labels=t{label}.index, "
+ "textprops={'fontsize':5}, radius=1.2)"
)
if label in 'ABCDE':
exec(f"axes['{label}'].set_title('product_{label}')")
else:
exec(f"axes['{label}'].set_title(source_top5['{label}'])")
# axes['T'].set_title('商品各渠道来源分布 & 渠道各商品销量分布', loc='left')
plt.show()
# 八、 staff vs sku、sources 切片分析
def plot_stack_bar(title, hue_index, data):
bar = pyc.Bar(
init_opts=opts.InitOpts(theme=glbs.ThemeType.DARK, width='100%', height='360px', bg_color='#1a1c1d')
).add_xaxis(
list(data[hue_index[0]].index)
)
for s in hue_index:
bar.add_yaxis(
s,
list(data[s]),
stack='stack0',
bar_width='60%'
)
bar.set_series_opts(
label_opts=opts.LabelOpts(is_show=False)
).set_global_opts(
legend_opts=opts.LegendOpts(pos_left='right', pos_top='top', orient='vertical'),
title_opts=opts.TitleOpts(title=title)
)
bar.options['xAxis'][0].update({'axisLabel': {'rotate': 90}})
return bar
title='员工订单量 - 来源切片'
hue_index = list(df_pruned['客户来源'].value_counts().head(5).index)
data = df_pruned.groupby(['客户来源', '回访人'])['订单金额'].count()
bar = plot_stack_bar(title, hue_index, data)
bar.render('员工vs客户来源.html')
title='员工订单量 - SKU 切片'
hue_index = list(df_pruned['商品名称'].value_counts().head(5).index)
data = df_pruned.groupby(['商品名称', '回访人'])['订单金额'].count()
bar = plot_stack_bar(title, hue_index, data)
bar.render('员工vs商品名称.html')
(1)地区销售情况对比
如图,包含总销售额、订单平均销售额和订单量三个维度的数据,点击图例可切换。其中总销售额和订单量最高的是江苏、山东、河南、辽宁几个省份,其次是河北、四川和广东。观察订单均价数据可以看到,对总销售额贡献较大的地区,订单均价都偏低。可以进一步分析的问题主要有:
- 当前商品售价是否处于最佳水平?偏离多少?
- 是否可以通过调整商品价格、开发的新的 SKU 以提高订单量和销售额?
- 相应地区的消费潜力是否充分挖掘?
- 是否可以策划营销活动、定向宣传,提高相应地区的销量?
- …
另外注意到西藏自治区的订单均价偏高,是由于样本数量太小产生的误差,不作考虑。
(2)用户下单行为分析
如图,左右分别为 0-12 和 12-24 小时中的下单数量分布,可以直观地看到有较高的集中趋势。根据此行为习惯,可以在对应时段提高商品 pv,增加客服销售人员支持,促进用户下单和提高转化率,以提高销售业绩。
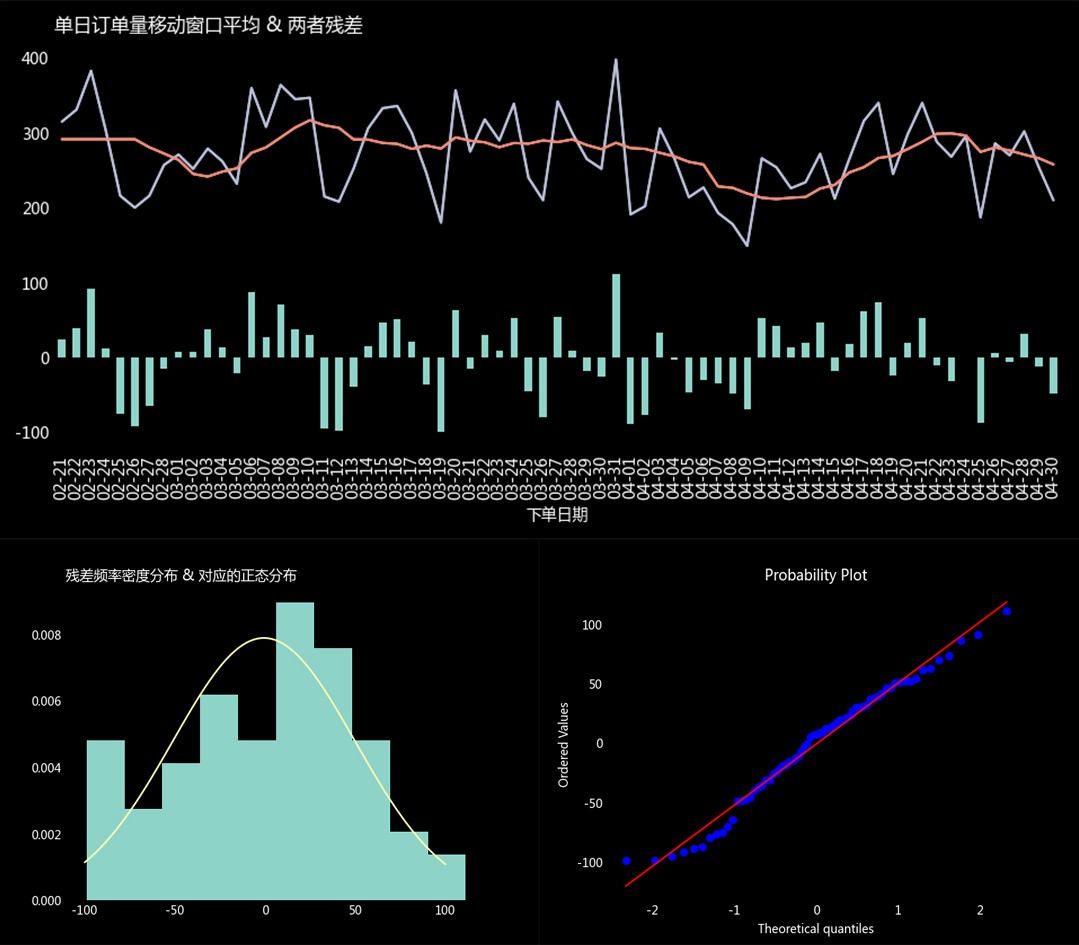
(3)单日销量异常检测
如图(上),为每日订单量折线图及其移动窗口平均,条形图为两者之差。通过平滑处理后可以看到整体呈平稳波动趋势。图(左下)为残差的频数密度分布,对比通过矩估计得到的总体正态分布(假设为正态总体)密度曲线。可以看到基本拟合正态分布,但存在异常值,图(右下)为 Q-Q 图,同样显示类似情况。
进一步分析残差条形图,发现每周末为一个谷值。04-05 ~ 04-09 出现一个异常的谷值,经查询时值清明假期。因此订单量的波动属于正常的节假日波动,业务水平呈总体平稳趋势。
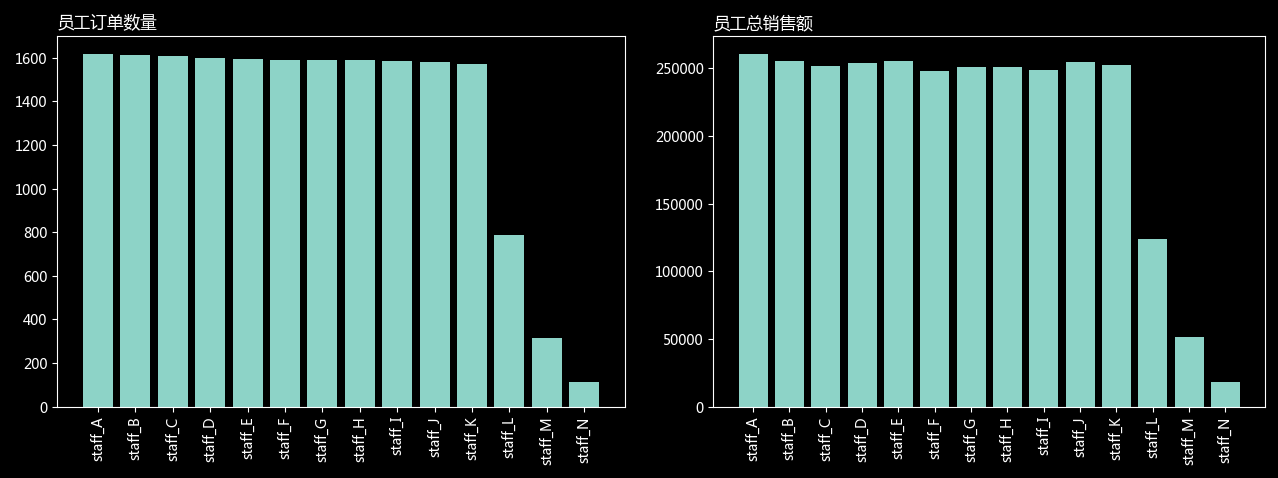
(4)员工销售情况分析
如图,为不同员工的销售额和订单量,大体上处于一致的水平。其中 L、M、N 三个员工业绩明显偏低,经查询是由于在岗时间导致,并无异常。
进一步进行切片分析,如下图,可以看到每个员工不同渠道和不同产品的销量分布也大体一致。
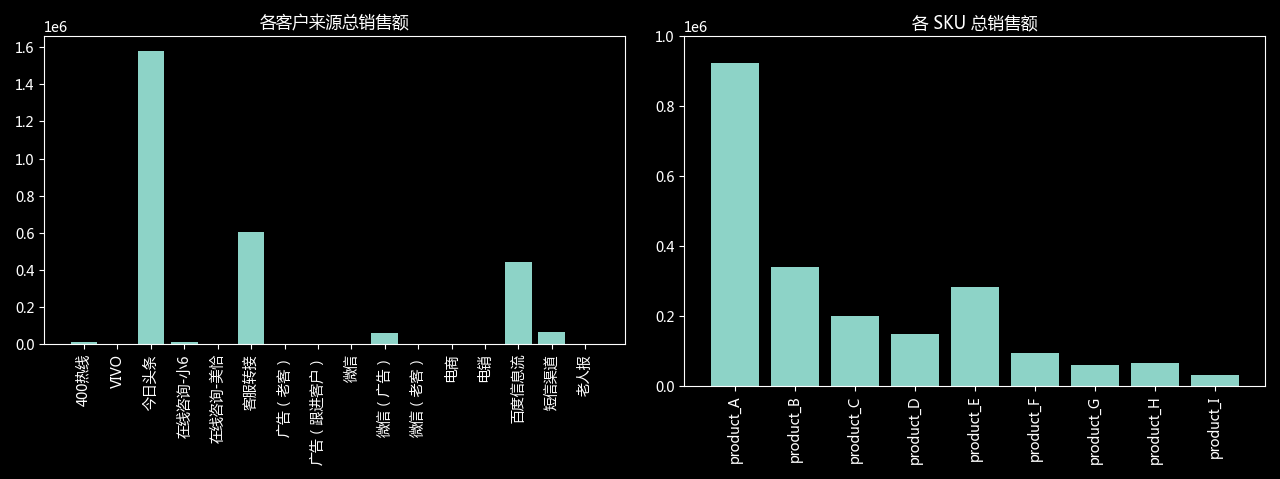
(5)渠道与 SKU 关联分析
如图为总样本不同渠道和不同 SKU 的销售额,趋势过于集中,容易因为某个渠道或某个产品的问题引起销售额较大的波动。因此适宜在巩固现有主力的前提下,开发和强化助力的渠道和产品。
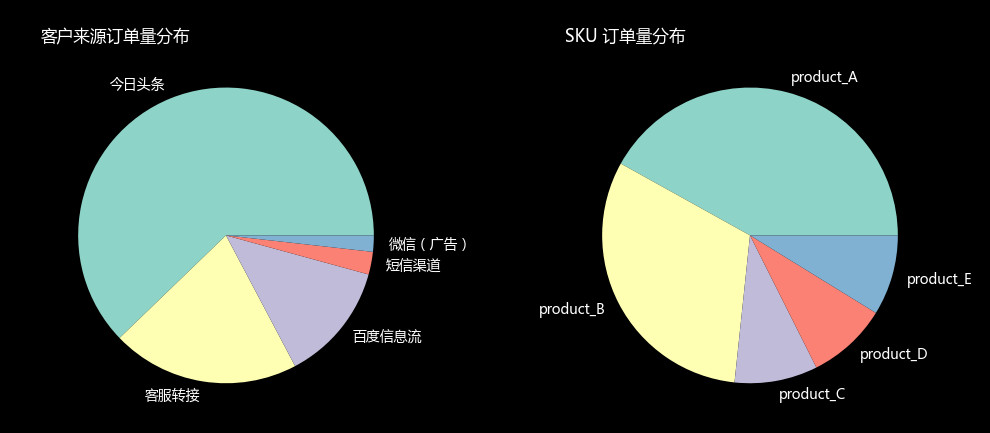
进一步分析,下图分别为总样本的订单量分布和对两个维度切片的订单量分布(取前五名类别进行切片)。通过两个维度切片进行关联分析,可以看到产品C与客服转接渠道、产品E与百度信息流渠道有明显对应关系(不同于总样本和其他切片)。因此可以进一步研究其特点,结合地区销售情况,用户行为习惯等分析,推出营销活动,作为提高销售业绩的突破口。
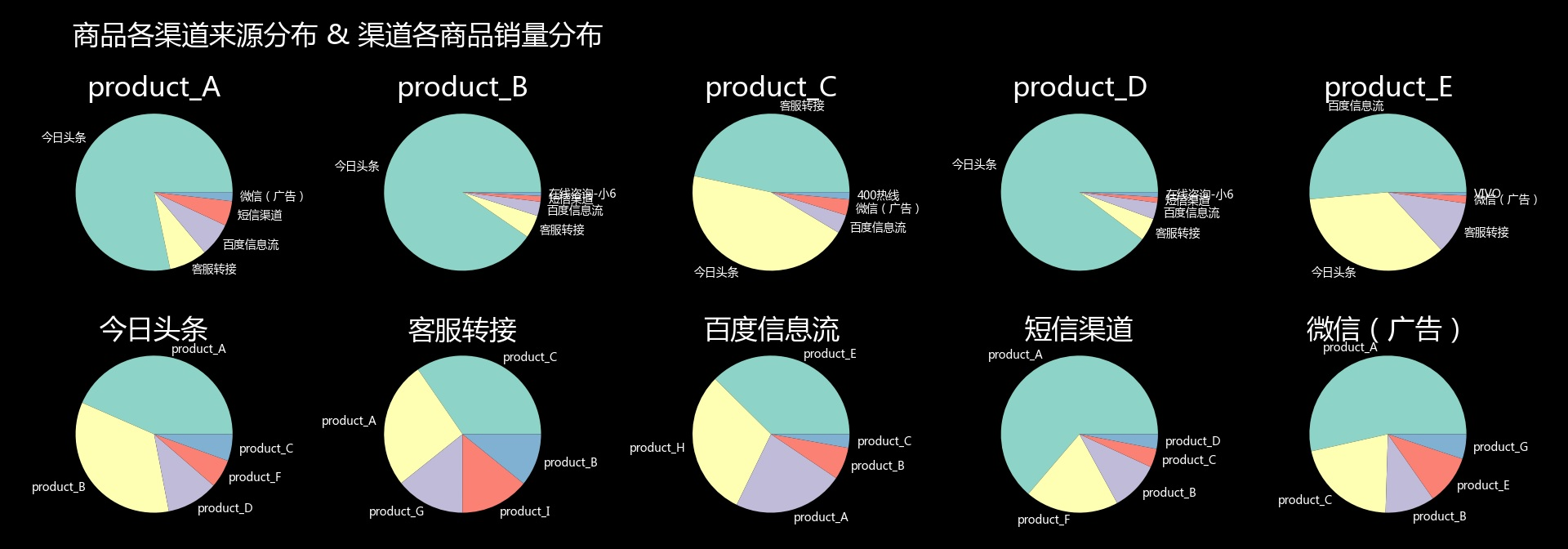
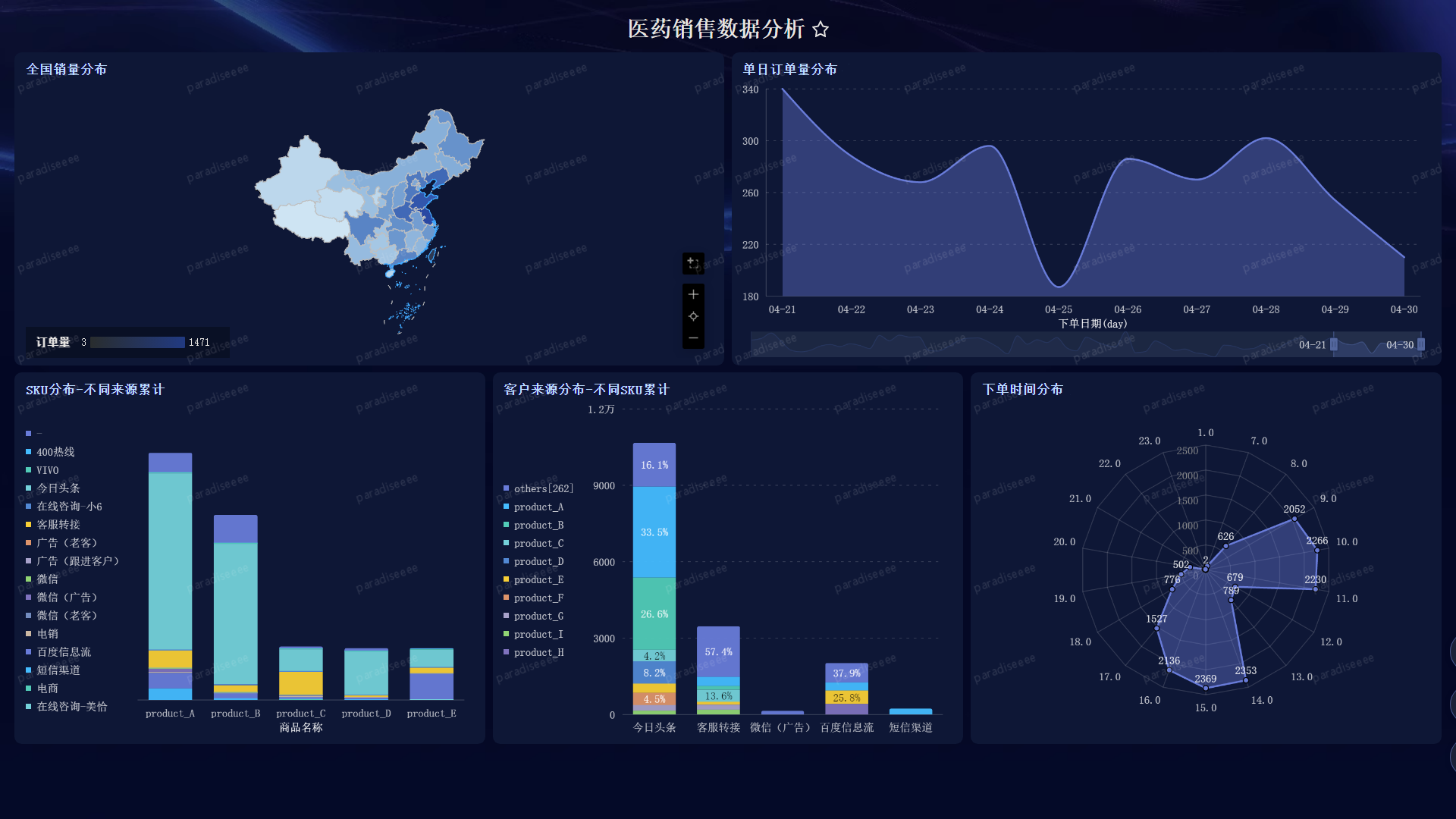
四、使用 Quick BI 创建可视化仪表板
最后探索性地使用一下阿里云提供的 Quick BI,与 PowerBI、Tableau 等工具类似,通过面板进行拖拽选项设置等操作,无代码完成可视化过程。对于常规的可视化图形,可以快速实现,并且风格自适应,省去很多调整操作。但是对于复杂的高度定制化的图表,操作难度过大,文档也不够完备便捷,还是代码工具更加好用。以下为简单的示例:
END